General Middleware
Creating Linear Regression Models using Python
Let’s go through a case study in detail to find how the Linear Regression Models are created, based on certain dataset. Use the below dataset for reference.
Anime Rating Case Study
Context
Streamist is a streaming company that streams web series and movies for a worldwide audience. Every content on their portal is rated by the viewers, and the portal also provides other information for the content like the number of people who have watched it, the number of people who want to watch it, the number of episodes, duration of an episode, etc.
They are currently focusing on the anime available in their portal, and want to identify the most important factors involved in rating an anime. You as a data scientist at Streamist are tasked with identifying the important factors and building a predictive model to predict the rating on an anime.
Objective
To analyze the data and build a linear regression model to predict the ratings of anime.
Key Questions
- What are the key factors influencing the rating of an anime?
- Is there a good predictive model for the rating of an anime? What does the performance assessment look like for such a model?
Data Information
Each record in the database provides a description of an anime. A detailed data dictionary can be found below.
Data Dictionary
- title – the title of anime
- description – the synopsis of the plot
- mediaType – format of publication
- eps – number of episodes (movies are considered 1 episode)
- duration – duration of an episode in minutes
- ongoing – whether it is ongoing
- sznOfRelease – the season of release (Winter, Spring, Fall)
- years_running – number of years the anime ran/is running
- studio_primary – primary studio of production
- studios_colab – whether there was a collaboration between studios to produce the anime
- contentWarn – whether anime has a content warning
- watched – number of users that completed it
- watching – number of users that are watching it
- wantWatch – number of users that want to watch it
- dropped – number of users that dropped it before completion
- rating – average user rating
- votes – number of votes that contribute to rating
- tag_Based_on_a_Manga – whether the anime is based on a manga
- tag_Comedy – whether the anime is of Comedy genre
- tag_Action – whether the anime is of Action genre
- tag_Fantasy – whether the anime is of Fantasy genre
- tag_Sci_Fi – whether the anime is of Sci-Fi genre
- tag_Shounen – whether the anime has a tag Shounen
- tag_Original_Work – whether the anime is an original work
- tag_Non_Human_Protagonists – whether the anime has any non-human protagonists
- tag_Drama – whether the anime is of Drama genre
- tag_Adventure – whether the anime is of Adventure genre
- tag_Family_Friendly – whether the anime is family-friendly
- tag_Short_Episodes – whether the anime has short episodes
- tag_School_Life – whether the anime is regarding school life
- tag_Romance – whether the anime is of Romance genre
- tag_Shorts – whether the anime has a tag Shorts
- tag_Slice_of_Life – whether the anime has a tag Slice of Life
- tag_Seinen – whether the anime has a tag Seinen
- tag_Supernatural – whether the anime has a tag Supernatural
- tag_Magic – whether the anime has a tag Magic
- tag_Animal_Protagonists – whether the anime has animal protagonists
- tag_Ecchi – whether the anime has a tag Ecchi
- tag_Mecha – whether the anime has a tag Mecha
- tag_Based_on_a_Light_Novel – whether the anime is based on a light novel
- tag_CG_Animation – whether the anime has a tag CG Animation
- tag_Superpowers – whether the anime has a tag Superpowers
- tag_Others – whether the anime has other tags
- tag_is_missing – whether tag is missing or not
Let’s start coding!
Import necessary libraries
In [1]:
# this will help in making the Python code more structured automatically (good coding practice)
%load_ext nb_black
# Libraries to help with reading and manipulating data
import numpy as np
import pandas as pd
# Libraries to help with data visualization
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
# Removes the limit for the number of displayed columns
pd.set_option("display.max_columns", None)
# Sets the limit for the number of displayed rows
pd.set_option("display.max_rows", 200)
# to split the data into train and test
from sklearn.model_selection import train_test_split
# to build linear regression_model
from sklearn.linear_model import LinearRegression
# to check model performance
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
In [2]:
# loading the dataset
df = pd.read_csv("anime_data.csv")
In [3]:
# checking shape of the data
print(f"There are {df.shape[0]} rows and {df.shape[1]} columns.")
There are 12101 rows and 44 columns.
In [4]:
# to view first 5 rows of the dataset df.head()
Out[4]:
| title | description | mediaType | eps | duration | ongoing | sznOfRelease | years_running | studio_primary | studios_colab | contentWarn | watched | watching | wantWatch | dropped | rating | votes | tag_Based_on_a_Manga | tag_Comedy | tag_Action | tag_Fantasy | tag_Sci_Fi | tag_Shounen | tag_Original_Work | tag_Non_Human_Protagonists | tag_Drama | tag_Adventure | tag_Family_Friendly | tag_Short_Episodes | tag_School_Life | tag_Romance | tag_Shorts | tag_Slice_of_Life | tag_Seinen | tag_Supernatural | tag_Magic | tag_Animal_Protagonists | tag_Ecchi | tag_Mecha | tag_Based_on_a_Light_Novel | tag_CG_Animation | tag_Superpowers | tag_Others | tag_missing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Fullmetal Alchemist: Brotherhood | The foundation of alchemy is based on the law … | TV | 64 | NaN | False | Spring | 1 | Bones | 0 | 1 | 103707.0 | 14351 | 25810 | 2656 | 4.702 | 86547 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | your name. | Mitsuha and Taki are two total strangers livin… | Movie | 1 | 107.0 | False | is_missing | 0 | Others | 0 | 0 | 58831.0 | 1453 | 21733 | 124 | 4.663 | 43960 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | A Silent Voice | After transferring into a new school, a deaf g… | Movie | 1 | 130.0 | False | is_missing | 0 | Kyoto Animation | 0 | 1 | 45892.0 | 946 | 17148 | 132 | 4.661 | 33752 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Haikyuu!! Karasuno High School vs Shiratorizaw… | Picking up where the second season ended, the … | TV | 10 | NaN | False | Fall | 0 | Production I.G | 0 | 0 | 25134.0 | 2183 | 8082 | 167 | 4.660 | 17422 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | Attack on Titan 3rd Season: Part II | The battle to retake Wall Maria begins now! Wi… | TV | 10 | NaN | False | Spring | 0 | Others | 0 | 1 | 21308.0 | 3217 | 7864 | 174 | 4.650 | 15789 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
In [5]:
# to view last 5 rows of the dataset df.tail()
Out[5]:
| title | description | mediaType | eps | duration | ongoing | sznOfRelease | years_running | studio_primary | studios_colab | contentWarn | watched | watching | wantWatch | dropped | rating | votes | tag_Based_on_a_Manga | tag_Comedy | tag_Action | tag_Fantasy | tag_Sci_Fi | tag_Shounen | tag_Original_Work | tag_Non_Human_Protagonists | tag_Drama | tag_Adventure | tag_Family_Friendly | tag_Short_Episodes | tag_School_Life | tag_Romance | tag_Shorts | tag_Slice_of_Life | tag_Seinen | tag_Supernatural | tag_Magic | tag_Animal_Protagonists | tag_Ecchi | tag_Mecha | tag_Based_on_a_Light_Novel | tag_CG_Animation | tag_Superpowers | tag_Others | tag_missing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 12096 | Sore Ike! Anpanman: Kirameke! Ice no Kuni no V… | Princess Vanilla is a princess in a land of ic… | Movie | 1 | NaN | False | is_missing | 0 | TMS Entertainment | 0 | 0 | 22.0 | 1 | 29 | 1 | 2.807 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12097 | Hulaing Babies Petit | NaN | TV | 12 | 5.0 | False | Winter | 0 | Others | 0 | 0 | 13.0 | 10 | 77 | 2 | 2.090 | 10 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12098 | Marco & The Galaxy Dragon | NaN | OVA | 1 | NaN | False | is_missing | 0 | is_missing | 0 | 0 | 17.0 | 0 | 65 | 0 | 2.543 | 10 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12099 | Xing Chen Bian 2nd Season | Second season of Xing Chen Bian. | Web | 3 | 24.0 | True | is_missing | 0 | is_missing | 0 | 0 | 40.5 | 31 | 22 | 0 | 3.941 | 10 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 12100 | Ultra B: Black Hole kara no Dokusaisha BB!! | NaN | Movie | 1 | 20.0 | False | is_missing | 0 | Shin-Ei Animation | 0 | 0 | 15.0 | 1 | 19 | 1 | 2.925 | 10 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Note:
1. The first section of the notebook is the section that has been covered in the previous case studies. For this session, this part can be skipped and we can directly refer to this summary of data cleaning steps and observations from EDA.
2. For this session, we will drop the missing values in the dataset. We will discuss better ways of dealing with missing values in the next session.
In [6]:
# let's create a copy of the data to avoid any changes to original data data = df.copy()
In [7]:
# checking for duplicate values in the data data.duplicated().sum()
Out[7]:
0
- There are no duplicate values in the data.
In [8]:
# checking the names of the columns in the data print(data.columns)
Index(['title', 'description', 'mediaType', 'eps', 'duration', 'ongoing',
'sznOfRelease', 'years_running', 'studio_primary', 'studios_colab',
'contentWarn', 'watched', 'watching', 'wantWatch', 'dropped', 'rating',
'votes', 'tag_Based_on_a_Manga', 'tag_Comedy', 'tag_Action',
'tag_Fantasy', 'tag_Sci_Fi', 'tag_Shounen', 'tag_Original_Work',
'tag_Non_Human_Protagonists', 'tag_Drama', 'tag_Adventure',
'tag_Family_Friendly', 'tag_Short_Episodes', 'tag_School_Life',
'tag_Romance', 'tag_Shorts', 'tag_Slice_of_Life', 'tag_Seinen',
'tag_Supernatural', 'tag_Magic', 'tag_Animal_Protagonists', 'tag_Ecchi',
'tag_Mecha', 'tag_Based_on_a_Light_Novel', 'tag_CG_Animation',
'tag_Superpowers', 'tag_Others', 'tag_missing'],
dtype='object')
In [9]:
# checking column datatypes and number of non-null values data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 12101 entries, 0 to 12100 Data columns (total 44 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 title 12101 non-null object 1 description 7633 non-null object 2 mediaType 12101 non-null object 3 eps 12101 non-null int64 4 duration 7465 non-null float64 5 ongoing 12101 non-null bool 6 sznOfRelease 12101 non-null object 7 years_running 12101 non-null int64 8 studio_primary 12101 non-null object 9 studios_colab 12101 non-null int64 10 contentWarn 12101 non-null int64 11 watched 12101 non-null float64 12 watching 12101 non-null int64 13 wantWatch 12101 non-null int64 14 dropped 12101 non-null int64 15 rating 12101 non-null float64 16 votes 12101 non-null int64 17 tag_Based_on_a_Manga 12101 non-null int64 18 tag_Comedy 12101 non-null int64 19 tag_Action 12101 non-null int64 20 tag_Fantasy 12101 non-null int64 21 tag_Sci_Fi 12101 non-null int64 22 tag_Shounen 12101 non-null int64 23 tag_Original_Work 12101 non-null int64 24 tag_Non_Human_Protagonists 12101 non-null int64 25 tag_Drama 12101 non-null int64 26 tag_Adventure 12101 non-null int64 27 tag_Family_Friendly 12101 non-null int64 28 tag_Short_Episodes 12101 non-null int64 29 tag_School_Life 12101 non-null int64 30 tag_Romance 12101 non-null int64 31 tag_Shorts 12101 non-null int64 32 tag_Slice_of_Life 12101 non-null int64 33 tag_Seinen 12101 non-null int64 34 tag_Supernatural 12101 non-null int64 35 tag_Magic 12101 non-null int64 36 tag_Animal_Protagonists 12101 non-null int64 37 tag_Ecchi 12101 non-null int64 38 tag_Mecha 12101 non-null int64 39 tag_Based_on_a_Light_Novel 12101 non-null int64 40 tag_CG_Animation 12101 non-null int64 41 tag_Superpowers 12101 non-null int64 42 tag_Others 12101 non-null int64 43 tag_missing 12101 non-null int64 dtypes: bool(1), float64(3), int64(35), object(5) memory usage: 4.0+ MB
- Dependent variable is the rating of an anime, which if of float type.
title,description,mediaType,sznOfRelease,studio_primaryare of object type.ongoingcolumn is of bool type.- All other columns are numeric in nature.
- There are missing values in the
descriptionanddurationcolumns.
Let’s check for missing values in the data.
In [10]:
# checking for missing values in the data data.isnull().sum()
Out[10]:
title 0 description 4468 mediaType 0 eps 0 duration 4636 ongoing 0 sznOfRelease 0 years_running 0 studio_primary 0 studios_colab 0 contentWarn 0 watched 0 watching 0 wantWatch 0 dropped 0 rating 0 votes 0 tag_Based_on_a_Manga 0 tag_Comedy 0 tag_Action 0 tag_Fantasy 0 tag_Sci_Fi 0 tag_Shounen 0 tag_Original_Work 0 tag_Non_Human_Protagonists 0 tag_Drama 0 tag_Adventure 0 tag_Family_Friendly 0 tag_Short_Episodes 0 tag_School_Life 0 tag_Romance 0 tag_Shorts 0 tag_Slice_of_Life 0 tag_Seinen 0 tag_Supernatural 0 tag_Magic 0 tag_Animal_Protagonists 0 tag_Ecchi 0 tag_Mecha 0 tag_Based_on_a_Light_Novel 0 tag_CG_Animation 0 tag_Superpowers 0 tag_Others 0 tag_missing 0 dtype: int64
durationcolumn has 4636 missing values, anddescriptioncolumn has 4468 missing values.- No other column has missing values.
In [11]:
# Let's look at the statistical summary of the data data.describe().T
Out[11]:
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| eps | 12101.0 | 13.393356 | 57.925097 | 1.000 | 1.000 | 2.000 | 12.000 | 2527.000 |
| duration | 7465.0 | 24.230141 | 31.468171 | 1.000 | 4.000 | 8.000 | 30.000 | 163.000 |
| years_running | 12101.0 | 0.283200 | 1.152234 | 0.000 | 0.000 | 0.000 | 0.000 | 51.000 |
| studios_colab | 12101.0 | 0.051649 | 0.221326 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| contentWarn | 12101.0 | 0.115362 | 0.319472 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| watched | 12101.0 | 2862.605694 | 7724.347024 | 0.000 | 55.000 | 341.000 | 2026.000 | 161567.000 |
| watching | 12101.0 | 256.334435 | 1380.840902 | 0.000 | 2.000 | 14.000 | 100.000 | 74537.000 |
| wantWatch | 12101.0 | 1203.681431 | 2294.327380 | 0.000 | 49.000 | 296.000 | 1275.000 | 28541.000 |
| dropped | 12101.0 | 151.568383 | 493.931710 | 0.000 | 3.000 | 12.000 | 65.000 | 19481.000 |
| rating | 12101.0 | 2.949037 | 0.827385 | 0.844 | 2.304 | 2.965 | 3.616 | 4.702 |
| votes | 12101.0 | 2088.124700 | 5950.332228 | 10.000 | 34.000 | 219.000 | 1414.000 | 131067.000 |
| tag_Based_on_a_Manga | 12101.0 | 0.290802 | 0.454151 | 0.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| tag_Comedy | 12101.0 | 0.272870 | 0.445453 | 0.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| tag_Action | 12101.0 | 0.231221 | 0.421631 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Fantasy | 12101.0 | 0.181555 | 0.385493 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Sci_Fi | 12101.0 | 0.166267 | 0.372336 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Shounen | 12101.0 | 0.144864 | 0.351978 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Original_Work | 12101.0 | 0.135195 | 0.341946 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Non_Human_Protagonists | 12101.0 | 0.112470 | 0.315957 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Drama | 12101.0 | 0.106107 | 0.307987 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Adventure | 12101.0 | 0.103793 | 0.305005 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Family_Friendly | 12101.0 | 0.097017 | 0.295993 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Short_Episodes | 12101.0 | 0.096934 | 0.295880 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_School_Life | 12101.0 | 0.092306 | 0.289470 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Romance | 12101.0 | 0.092141 | 0.289237 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Shorts | 12101.0 | 0.089662 | 0.285709 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Slice_of_Life | 12101.0 | 0.080820 | 0.272569 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Seinen | 12101.0 | 0.077101 | 0.266763 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Supernatural | 12101.0 | 0.070903 | 0.256674 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Magic | 12101.0 | 0.064292 | 0.245283 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Animal_Protagonists | 12101.0 | 0.060326 | 0.238099 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Ecchi | 12101.0 | 0.057433 | 0.232678 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Mecha | 12101.0 | 0.054541 | 0.227091 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Based_on_a_Light_Novel | 12101.0 | 0.053384 | 0.224807 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_CG_Animation | 12101.0 | 0.050079 | 0.218116 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Superpowers | 12101.0 | 0.044624 | 0.206486 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_Others | 12101.0 | 0.090654 | 0.287128 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| tag_missing | 12101.0 | 0.025866 | 0.158741 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
- We can see that the anime ratings vary between 0.844 and 4.702, which suggests that the anime were rated on a scale of 0-5.
- 50% of the anime in the data have a runtime less than or equal to 8 minutes.
- Some anime even have a runtime of 1 minute.
- This seems strange at first, but a Google search can reveal that there are indeed such anime.
- At least 75% of the anime have run for less than a year.
- This may be because the listed anime has few episodes only.
- At least 75% of the anime have no content warnings.
- The number of views for the anime in the data has a very wide range (0 to more than 160,000).
Let’s look at the non-numeric columns.
In [12]:
# filtering non-numeric columns cat_columns = data.select_dtypes(exclude=np.number).columns cat_columns
Out[12]:
Index(['title', 'description', 'mediaType', 'ongoing', 'sznOfRelease',
'studio_primary'],
dtype='object')
In [13]:
# we will skip the title and description columns as they will have a lot of unique values
cat_col = ["mediaType", "ongoing", "sznOfRelease", "studio_primary"]
# printing the number of occurrences of each unique value in each categorical column
for column in cat_col:
print(data[column].value_counts())
print("-" * 50)
TV 3993 Movie 1928 OVA 1770 Music Video 1290 Web 1170 DVD Special 803 Other 580 TV Special 504 is_missing 63 Name: mediaType, dtype: int64 -------------------------------------------------- False 11986 True 115 Name: ongoing, dtype: int64 -------------------------------------------------- is_missing 8554 Spring 1135 Fall 1011 Winter 717 Summer 684 Name: sznOfRelease, dtype: int64 -------------------------------------------------- Others 4340 is_missing 3208 Toei Animation 636 Sunrise 430 J.C. Staff 341 MADHOUSE 337 TMS Entertainment 317 Production I.G 271 Studio Deen 260 Studio Pierrot 221 OLM 210 A-1 Pictures 194 AIC 167 Shin-Ei Animation 164 Nippon Animation 145 Tatsunoko Production 144 DLE 130 GONZO 124 Bones 121 Shaft 118 XEBEC 117 Kyoto Animation 106 Name: studio_primary, dtype: int64 --------------------------------------------------
- Most of the anime in the data are either TV series or movies.
- Most of the anime in the data are not ongoing.
- The season of release is missing for most of the anime in the data.
- Toei Animation and Sunrise are the top two studios (excluding other studios and missing studios).
We will drop the title and description columns before moving forward as they have a lot of text in them.
In [14]:
data.drop(["title", "description"], axis=1, inplace=True)
We will drop the missing values in the dataset.
In [15]:
data.dropna(inplace=True) data.shape
Out[15]:
(7465, 42)
We will discuss better ways of dealing with missing values in the next session.
Let’s visualize the data
Univariate Analysis
In [16]:
# function to plot a boxplot and a histogram along the same scale.
def histogram_boxplot(data, feature, figsize=(12, 7), kde=False, bins=None):
"""
Boxplot and histogram combined
data: dataframe
feature: dataframe column
figsize: size of figure (default (12,7))
kde: whether to the show density curve (default False)
bins: number of bins for histogram (default None)
"""
f2, (ax_box2, ax_hist2) = plt.subplots(
nrows=2, # Number of rows of the subplot grid= 2
sharex=True, # x-axis will be shared among all subplots
gridspec_kw={"height_ratios": (0.25, 0.75)},
figsize=figsize,
) # creating the 2 subplots
sns.boxplot(
data=data, x=feature, ax=ax_box2, showmeans=True, color="violet"
) # boxplot will be created and a star will indicate the mean value of the column
sns.histplot(
data=data, x=feature, kde=kde, ax=ax_hist2, bins=bins, palette="winter"
) if bins else sns.histplot(
data=data, x=feature, kde=kde, ax=ax_hist2
) # For histogram
ax_hist2.axvline(
data[feature].mean(), color="green", linestyle="--"
) # Add mean to the histogram
ax_hist2.axvline(
data[feature].median(), color="black", linestyle="-"
) # Add median to the histogram
rating
In [17]:
histogram_boxplot(data, "rating")
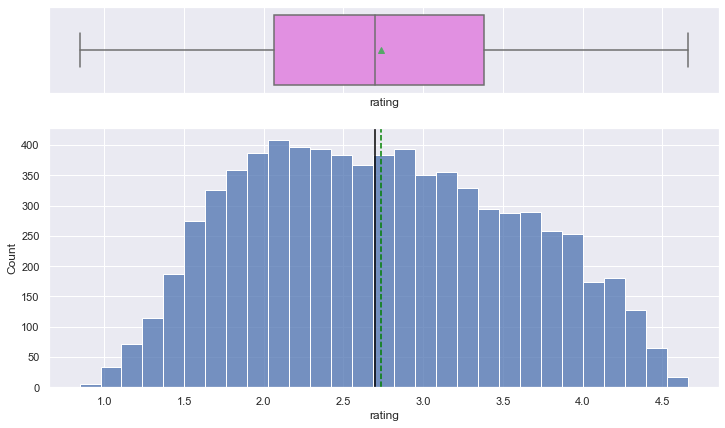
- The anime ratings are close to normally distributed.
eps
In [18]:
histogram_boxplot(data, "eps", bins=100)
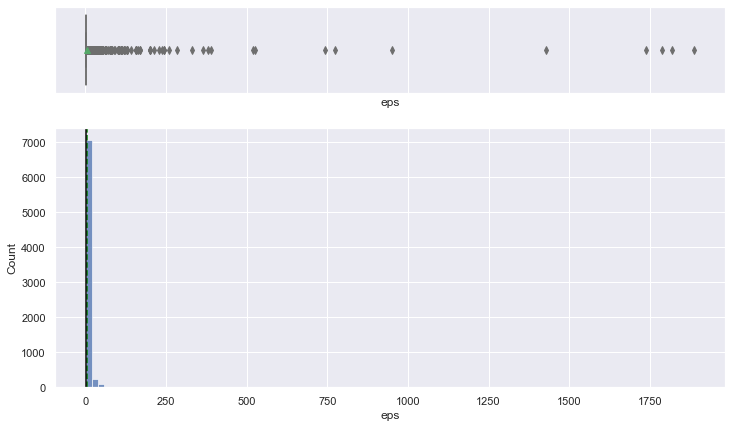
- The distribution is heavily right-skewed, as there are many anime movies in the data, and they are considered to be of only one episode (as per data description).
duration
In [19]:
histogram_boxplot(data, "duration")
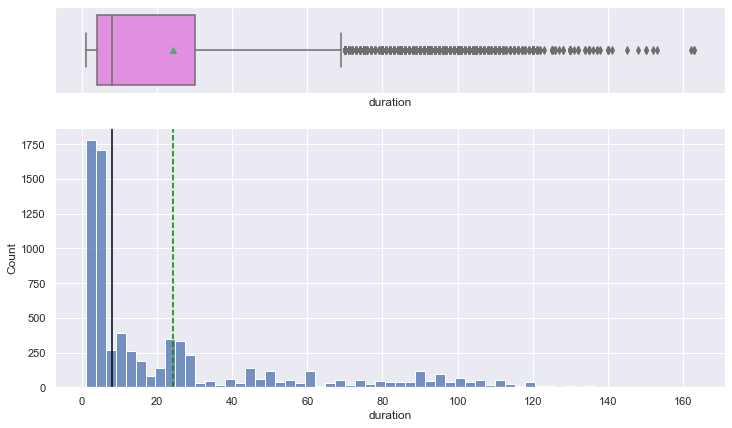
- The distribution is right-skewed with a median runtime of less than 10 minutes.
years_running
In [20]:
histogram_boxplot(data, "years_running")
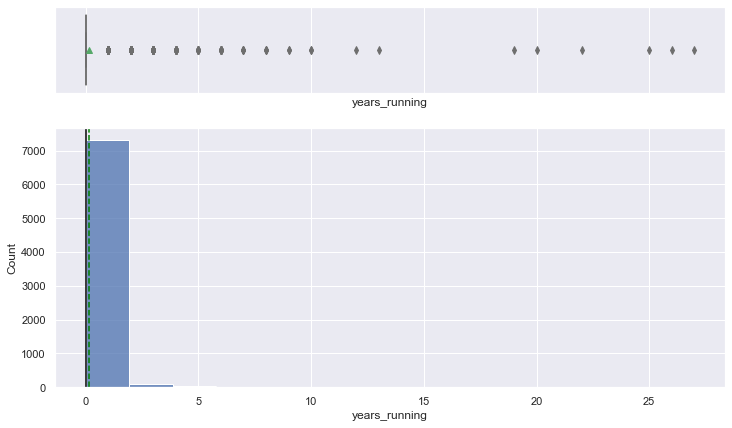
- The distribution is heavily right-skewed, and most of the anime have run for less than 1 year.
watched
In [21]:
histogram_boxplot(data, "watched", bins=50)
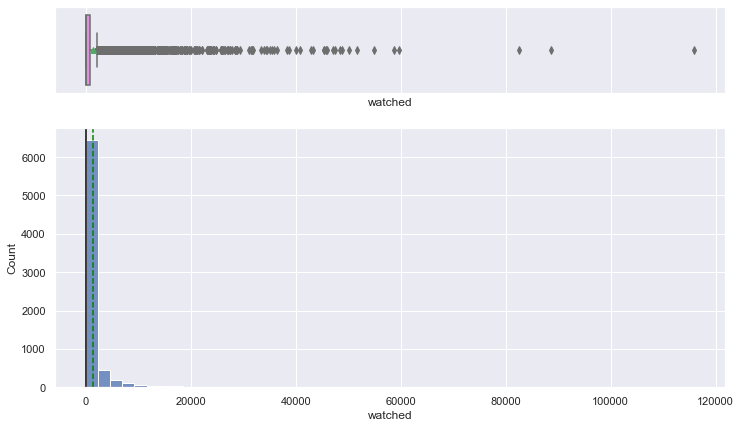
- The distribution is heavily right-skewed, and most of the anime having less than 500 viewers.
watching
In [22]:
histogram_boxplot(data, "watching", bins=50)
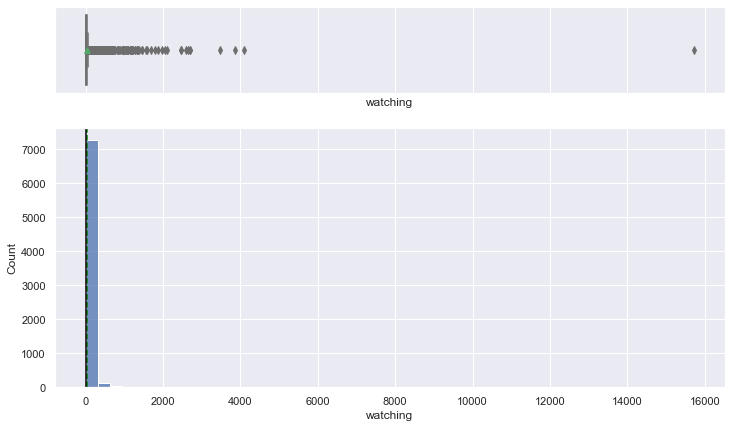
- The distribution is heavily right-skewed.
wantWatch
In [23]:
histogram_boxplot(data, "wantWatch", bins=50)
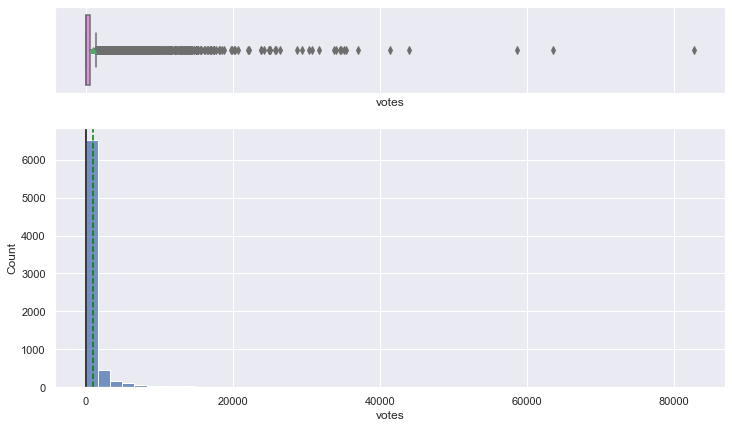
- The distribution is heavily right-skewed.
dropped
In [24]:
histogram_boxplot(data, "dropped", bins=50)
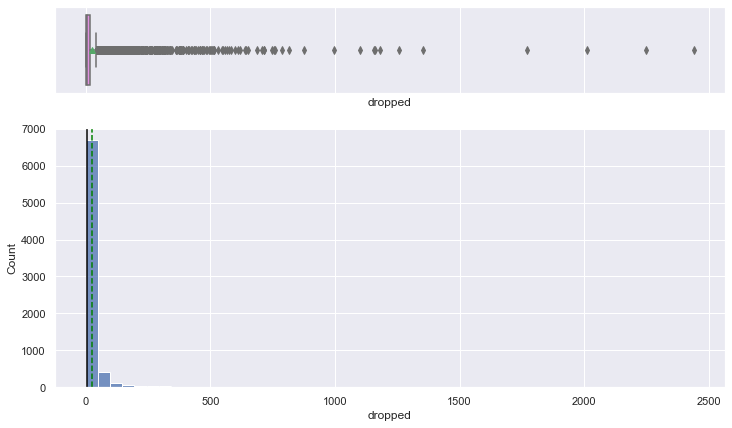
- The distribution is heavily right-skewed.
votes
In [25]:
histogram_boxplot(data, "votes", bins=50)
- The distribution is heavily right-skewed, and few shows have more than 5000 votes.
In [26]:
# function to create labeled barplots
def labeled_barplot(data, feature, perc=False, n=None):
"""
Barplot with percentage at the top
data: dataframe
feature: dataframe column
perc: whether to display percentages instead of count (default is False)
n: displays the top n category levels (default is None, i.e., display all levels)
"""
total = len(data[feature]) # length of the column
count = data[feature].nunique()
if n is None:
plt.figure(figsize=(count + 1, 5))
else:
plt.figure(figsize=(n + 1, 5))
plt.xticks(rotation=90, fontsize=15)
ax = sns.countplot(
data=data,
x=feature,
palette="Paired",
order=data[feature].value_counts().index[:n].sort_values(),
)
for p in ax.patches:
if perc == True:
label = "{:.1f}%".format(
100 * p.get_height() / total
) # percentage of each class of the category
else:
label = p.get_height() # count of each level of the category
x = p.get_x() + p.get_width() / 2 # width of the plot
y = p.get_height() # height of the plot
ax.annotate(
label,
(x, y),
ha="center",
va="center",
size=12,
xytext=(0, 5),
textcoords="offset points",
) # annotate the percentage
plt.show() # show the plot
mediaType
In [27]:
labeled_barplot(data, "mediaType", perc=True)
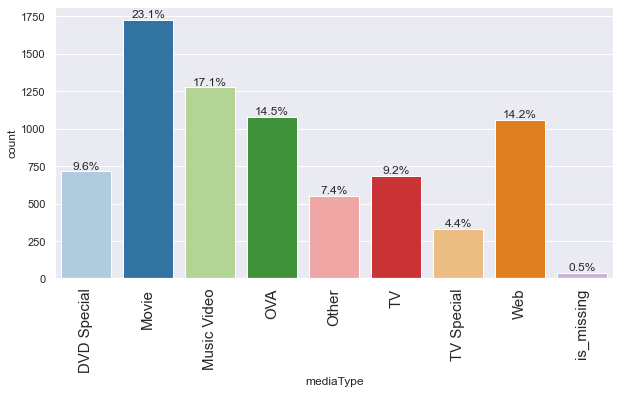
- Distribution of the media types has changed a lot after dropping the rows with missing values.
- Most of the anime now are movies or music videos.
ongoing
In [28]:
labeled_barplot(data, "ongoing", perc=True)
- Very few anime in the data are ongoing.
sznOfRelease
In [29]:
labeled_barplot(data, "sznOfRelease", perc=True)
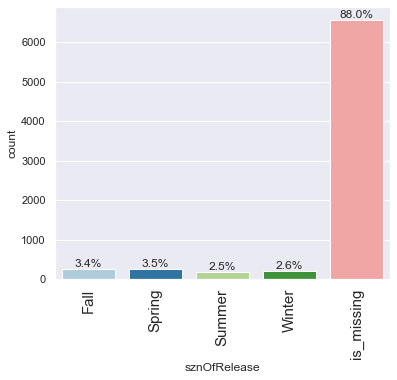
- The season of release of anime is spread out across all seasons when the value is available.
studio_primary
In [30]:
labeled_barplot(data, "studio_primary", perc=True)
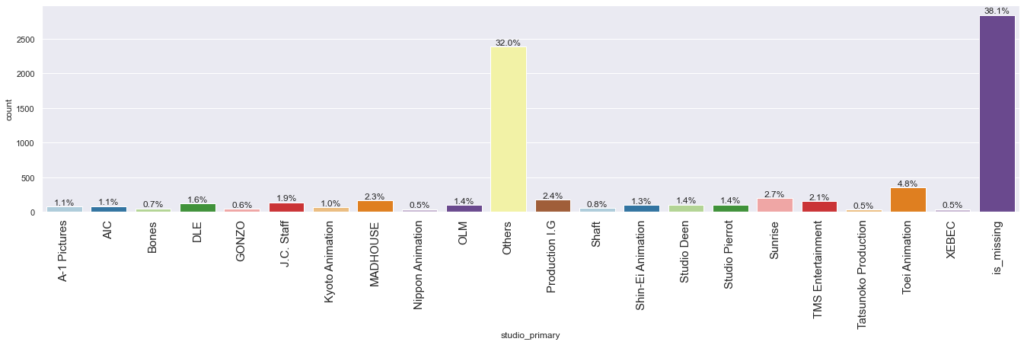
- Toei Animation is the most common studio among the available studio names.
studios_colab
In [31]:
labeled_barplot(data, "studios_colab", perc=True)
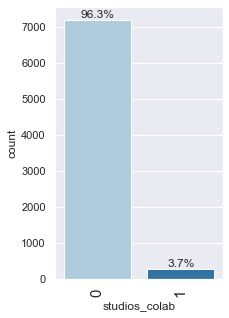
- More than 95% of the anime in the data do not involve a collaboration between studios.
contentWarn
In [32]:
labeled_barplot(data, "contentWarn", perc=True)
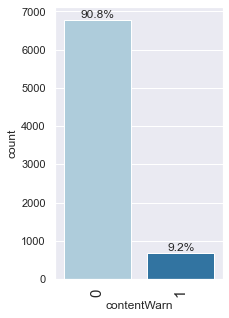
- ~9% of the anime in the data have an associated content warning.
In [33]:
# creating a list of tag columns
tag_cols = [item for item in data.columns if "tag" in item]
# printing the number of occurrences of each unique value in each categorical column
for column in tag_cols:
print(data[column].value_counts())
print("-" * 50)
0 5718 1 1747 Name: tag_Based_on_a_Manga, dtype: int64 -------------------------------------------------- 0 5545 1 1920 Name: tag_Comedy, dtype: int64 -------------------------------------------------- 0 6227 1 1238 Name: tag_Action, dtype: int64 -------------------------------------------------- 0 6342 1 1123 Name: tag_Fantasy, dtype: int64 -------------------------------------------------- 0 6511 1 954 Name: tag_Sci_Fi, dtype: int64 -------------------------------------------------- 0 6625 1 840 Name: tag_Shounen, dtype: int64 -------------------------------------------------- 0 6548 1 917 Name: tag_Original_Work, dtype: int64 -------------------------------------------------- 0 6553 1 912 Name: tag_Non_Human_Protagonists, dtype: int64 -------------------------------------------------- 0 6896 1 569 Name: tag_Drama, dtype: int64 -------------------------------------------------- 0 6913 1 552 Name: tag_Adventure, dtype: int64 -------------------------------------------------- 0 6736 1 729 Name: tag_Family_Friendly, dtype: int64 -------------------------------------------------- 0 6292 1 1173 Name: tag_Short_Episodes, dtype: int64 -------------------------------------------------- 0 7029 1 436 Name: tag_School_Life, dtype: int64 -------------------------------------------------- 0 6978 1 487 Name: tag_Romance, dtype: int64 -------------------------------------------------- 0 6386 1 1079 Name: tag_Shorts, dtype: int64 -------------------------------------------------- 0 6875 1 590 Name: tag_Slice_of_Life, dtype: int64 -------------------------------------------------- 0 7019 1 446 Name: tag_Seinen, dtype: int64 -------------------------------------------------- 0 7035 1 430 Name: tag_Supernatural, dtype: int64 -------------------------------------------------- 0 7132 1 333 Name: tag_Magic, dtype: int64 -------------------------------------------------- 0 6885 1 580 Name: tag_Animal_Protagonists, dtype: int64 -------------------------------------------------- 0 7159 1 306 Name: tag_Ecchi, dtype: int64 -------------------------------------------------- 0 7189 1 276 Name: tag_Mecha, dtype: int64 -------------------------------------------------- 0 7224 1 241 Name: tag_Based_on_a_Light_Novel, dtype: int64 -------------------------------------------------- 0 6985 1 480 Name: tag_CG_Animation, dtype: int64 -------------------------------------------------- 0 7218 1 247 Name: tag_Superpowers, dtype: int64 -------------------------------------------------- 0 6521 1 944 Name: tag_Others, dtype: int64 -------------------------------------------------- 0 7184 1 281 Name: tag_missing, dtype: int64 --------------------------------------------------
- There are 1747 anime that are based on manga.
- There are 1920 anime of the Comedy genre.
- There are 1079 anime of the Romance genre.
Bivariate analysis
We will not consider the tag columns for correlation check as they have only 0 or 1 values.
In [34]:
# creating a list of non-tag columns corr_cols = [item for item in data.columns if "tag" not in item] print(corr_cols)
['mediaType', 'eps', 'duration', 'ongoing', 'sznOfRelease', 'years_running', 'studio_primary', 'studios_colab', 'contentWarn', 'watched', 'watching', 'wantWatch', 'dropped', 'rating', 'votes']
In [35]:
plt.figure(figsize=(15, 7))
sns.heatmap(
df[corr_cols].corr(), annot=True, vmin=-1, vmax=1, fmt=".2f", cmap="Spectral"
)
plt.show()
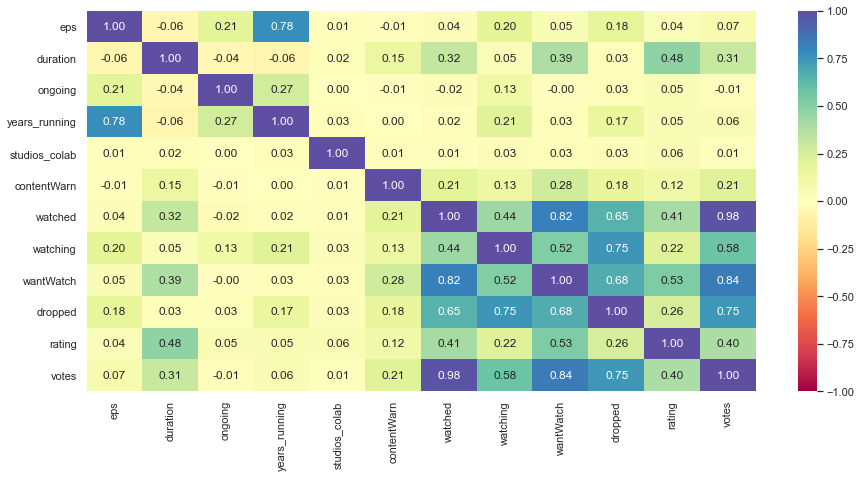
watchedandwantWatchcolumns are highly correlated.watchedandvotescolumns are very highly correlated.wantWatchandvotescolumns are highly correlated.
Checking the relation of different variables with rating
Note – Double click on the below plot to zoom the image. Or you can open the below plot in a new tab for better visibilty
In [36]:
plt.figure(figsize=(20, 5)) sns.pairplot(df, y_vars="rating") plt.show()
<Figure size 1440x360 with 0 Axes>

- Duration, ongoing, watched columns tend to show an increasing trend which means if there is an increase in the respective column there would be an increase in the rating.
- Content warning tend to show the decreasing trend.
Let’s check the variation in rating with some of the categorical columns in our data
mediaType vs rating
In [37]:
plt.figure(figsize=(10, 5)) sns.boxplot(x="mediaType", y="rating", data=data) plt.show()
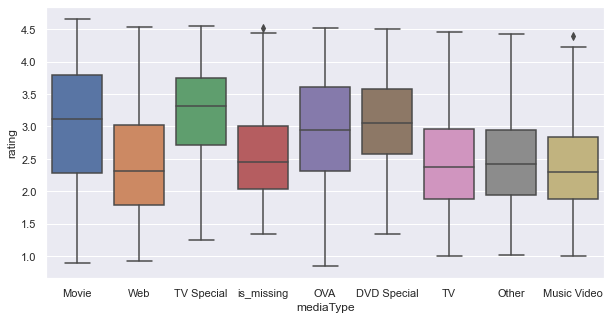
- Anime available as TV series, web series, or music videos have a lower rating in general.
sznOfRelease vs rating
In [38]:
plt.figure(figsize=(10, 5)) sns.boxplot(x="sznOfRelease", y="rating", data=data) plt.show()
- Anime ratings have a similar distribution across all the seasons of release.
studio_primary vs rating
In [39]:
plt.figure(figsize=(15, 5)) sns.boxplot(x="studio_primary", y="rating", data=data) plt.xticks(rotation=90) plt.show()
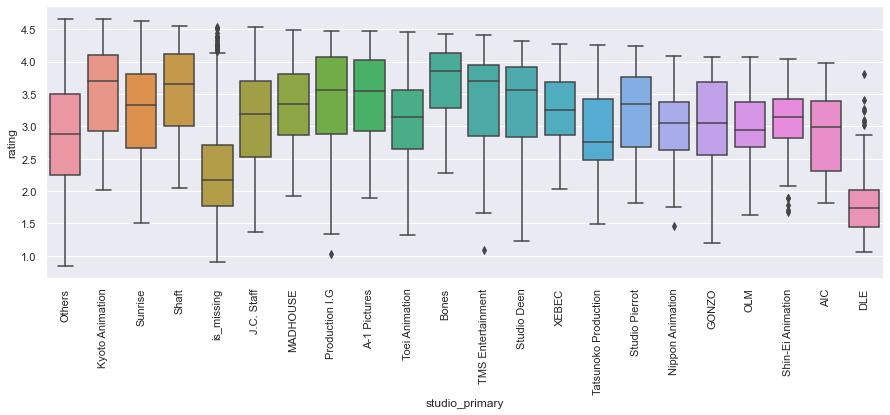
- In general, the ratings are low for anime produced by DLE studios.
- Ratings are also low, in general, for anime produced by studios other than the ones in the data.
Summary of EDA
Data Description:
- The target variable (
rating) is of float type. title,description,mediaType,sznOfRelease, andstudio_primaryare of object type.ongoingcolumn is of bool type.- All other columns are numeric in nature.
- The
titleanddescriptioncolumns are dropped for modeling as they are highly textual in nature. - There are no duplicate values in the data.
- There are missing values in the data. The rows with missing data have been dropped.
Observations from EDA:
rating: The anime ratings are close to normally distributed, with a mean rating of 2.74. The rating increases with an increase in the number of people who have watched or want to watch the anime.eps: The distribution is heavily right-skewed as there are many anime movies in the data (at least 50%), and they are considered to be of only one episode as per data description. The number of episodes increases as the anime runs for more years.duration: The distribution is right-skewed with a median anime runtime of less than 10 minutes. With the increase in rating, the duration increases.years_running: The distribution is heavily right-skewed, and at least 75% of the anime have run for less than 1 year.watched: The distribution is heavily right-skewed, and most of the anime have less than 500 viewers. This attribute is highly correlated with thewantWatchandvotesattributes.watching: The distribution is heavily right-skewed and highly correlated with thedroppedattribute.wantWatch: The distribution is heavily right-skewed with a median value of 132 potential watchers.dropped: The distribution is heavily right-skewed with a drop of 25 viewers on average.votes: The distribution is heavily right-skewed, and few shows have more than 5000 votes.mediaType: 23% of the anime are published for TV, 17% as music videos, and 14% as web series. Anime available as TV series, web series, or music videos have a lower rating in generalongoing: Less than 1% of the anime in the data are ongoing.sznOfRelease: The season of release is missing for nearly 90% of the anime in the data, and is spread out almost evenly across all seasons when available. Anime ratings have a similar distribution across all the seasons of release.studio_primary: Nearly 40% of the anime in the data are produced by studios not listed in the data. Toei Animation is the most common studio among the available studio names. In general, the ratings are low for anime produced by DLE studios and studios other than the ones listed in the data.studios_colab: More than 95% of the anime in the data do not involve collaboration between studios.contentWarn: Less than 10% of the anime in the data have an associated content warning.tag_<tag/genre>: There are 1747 anime that are based on manga, 1920 of the Comedy genre, 1238 of the Action genre, 1079 anime of the Romance genre, and more.
Model Building
Define independent and dependent variables
In [40]:
X = data.drop(["rating"], axis=1) y = data["rating"]
Creating dummy variables
In [41]:
X = pd.get_dummies(
X,
columns=X.select_dtypes(include=["object", "category"]).columns.tolist(),
drop_first=True,
)
X.head()
Out[41]:
| eps | duration | ongoing | years_running | studios_colab | contentWarn | watched | watching | wantWatch | dropped | votes | tag_Based_on_a_Manga | tag_Comedy | tag_Action | tag_Fantasy | tag_Sci_Fi | tag_Shounen | tag_Original_Work | tag_Non_Human_Protagonists | tag_Drama | tag_Adventure | tag_Family_Friendly | tag_Short_Episodes | tag_School_Life | tag_Romance | tag_Shorts | tag_Slice_of_Life | tag_Seinen | tag_Supernatural | tag_Magic | tag_Animal_Protagonists | tag_Ecchi | tag_Mecha | tag_Based_on_a_Light_Novel | tag_CG_Animation | tag_Superpowers | tag_Others | tag_missing | mediaType_Movie | mediaType_Music Video | mediaType_OVA | mediaType_Other | mediaType_TV | mediaType_TV Special | mediaType_Web | mediaType_is_missing | sznOfRelease_Spring | sznOfRelease_Summer | sznOfRelease_Winter | sznOfRelease_is_missing | studio_primary_AIC | studio_primary_Bones | studio_primary_DLE | studio_primary_GONZO | studio_primary_J.C. Staff | studio_primary_Kyoto Animation | studio_primary_MADHOUSE | studio_primary_Nippon Animation | studio_primary_OLM | studio_primary_Others | studio_primary_Production I.G | studio_primary_Shaft | studio_primary_Shin-Ei Animation | studio_primary_Studio Deen | studio_primary_Studio Pierrot | studio_primary_Sunrise | studio_primary_TMS Entertainment | studio_primary_Tatsunoko Production | studio_primary_Toei Animation | studio_primary_XEBEC | studio_primary_is_missing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 107.0 | False | 0 | 0 | 0 | 58831.0 | 1453 | 21733 | 124 | 43960 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 130.0 | False | 0 | 0 | 1 | 45892.0 | 946 | 17148 | 132 | 33752 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 1 | 111.0 | False | 0 | 0 | 0 | 8454.0 | 280 | 6624 | 150 | 6254 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 27 | 1 | 125.0 | False | 0 | 0 | 0 | 115949.0 | 589 | 12388 | 161 | 82752 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 31 | 1 | 117.0 | False | 0 | 0 | 0 | 35896.0 | 538 | 15651 | 130 | 26465 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
In [42]:
X.shape
Out[42]:
(7465, 71)
Split the data into train and test
In [43]:
# splitting the data in 70:30 ratio for train to test data x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
In [44]:
print("Number of rows in train data =", x_train.shape[0])
print("Number of rows in test data =", x_test.shape[0])
Number of rows in train data = 5225 Number of rows in test data = 2240
Fitting a linear model
In [45]:
lin_reg_model = LinearRegression() lin_reg_model.fit(x_train, y_train)
Out[45]:
LinearRegression()
Model performance check
- We will be using metric functions defined in sklearn for RMSE, MAE, and R2�2.
- We will define functions to calculate adjusted R2�2 and MAPE.
- The mean absolute percentage error (MAPE) measures the accuracy of predictions as a percentage, and can be calculated as the average absolute percent error for each predicted value minus actual values divided by actual values. It works best if there are no extreme values in the data and none of the actual values are 0.
- We will create a function that will print out all the above metrics in one go.
In [46]:
# function to compute adjusted R-squared
def adj_r2_score(predictors, targets, predictions):
r2 = r2_score(targets, predictions)
n = predictors.shape[0]
k = predictors.shape[1]
return 1 - ((1 - r2) * (n - 1) / (n - k - 1))
# function to compute MAPE
def mape_score(targets, predictions):
return np.mean(np.abs(targets - predictions) / targets) * 100
# function to compute different metrics to check performance of a regression model
def model_performance_regression(model, predictors, target):
"""
Function to compute different metrics to check regression model performance
model: regressor
predictors: independent variables
target: dependent variable
"""
# predicting using the independent variables
pred = model.predict(predictors)
r2 = r2_score(target, pred) # to compute R-squared
adjr2 = adj_r2_score(predictors, target, pred) # to compute adjusted R-squared
rmse = np.sqrt(mean_squared_error(target, pred)) # to compute RMSE
mae = mean_absolute_error(target, pred) # to compute MAE
mape = mape_score(target, pred) # to compute MAPE
# creating a dataframe of metrics
df_perf = pd.DataFrame(
{
"RMSE": rmse,
"MAE": mae,
"R-squared": r2,
"Adj. R-squared": adjr2,
"MAPE": mape,
},
index=[0],
)
return df_perf
In [47]:
# Checking model performance on train set
print("Training Performance\n")
lin_reg_model_train_perf = model_performance_regression(lin_reg_model, x_train, y_train)
lin_reg_model_train_perf
Training Performance
Out[47]:
| RMSE | MAE | R-squared | Adj. R-squared | MAPE | |
|---|---|---|---|---|---|
| 0 | 0.57729 | 0.467123 | 0.52152 | 0.514927 | 19.550725 |
In [48]:
# Checking model performance on test set
print("Test Performance\n")
lin_reg_model_test_perf = model_performance_regression(lin_reg_model, x_test, y_test)
lin_reg_model_test_perf
Test Performance
Out[48]:
| RMSE | MAE | R-squared | Adj. R-squared | MAPE | |
|---|---|---|---|---|---|
| 0 | 0.569001 | 0.463416 | 0.515888 | 0.500034 | 19.386434 |
Observations
- The train and test R2�2 are 0.522 and 0.516, indicating that the model explains 52.2% and 51.6% of the total variation in the train and test sets respectively. Also, both scores are comparable.
- RMSE values on the train and test sets are also comparable.
- This shows that the model is not overfitting.
- MAE indicates that our current model is able to predict anime ratings within a mean error of 0.46
- MAPE of 19.4 on the test data means that we are able to predict within 19.4% of the anime rating.
- However, the overall performance is not so great.
Forward Feature Selection using SequentialFeatureSelector
We will see how to select a subset of important features with forward feature selection using SequentialFeatureSelector.
Why should we do feature selection?
- Reduces dimensionality
- Discards deceptive features (Deceptive features appear to aid learning on the training set, but impair generalization)
- Speeds training/testing
How does forward feature selection work?
- It starts with an empty model and adds variables one by one.
- In each forward step, you add the one variable that gives the highest improvement to your model.
We’ll use forward feature selection on all the variables
In [49]:
# please uncomment and run the next line if mlxtend library is not previously installed #!pip install mlxtend
In [50]:
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
reg = LinearRegression()
# Build step forward feature selection
sfs = SFS(
reg,
k_features=x_train.shape[1],
forward=True, # k_features denotes the number of features to select
floating=False,
scoring="r2",
n_jobs=-1, # n_jobs=-1 means all processor cores will be used
verbose=2,
cv=5,
)
# Perform SFFS
sfs = sfs.fit(x_train, y_train)
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.6s [Parallel(n_jobs=-1)]: Done 71 out of 71 | elapsed: 1.7s finished [2022-04-12 17:55:50] Features: 1/71 -- score: 0.261089359587903[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.0s [Parallel(n_jobs=-1)]: Done 55 out of 70 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 70 out of 70 | elapsed: 0.1s finished [2022-04-12 17:55:50] Features: 2/71 -- score: 0.3522663085348247[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 54 out of 69 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 69 out of 69 | elapsed: 0.2s finished [2022-04-12 17:55:50] Features: 3/71 -- score: 0.4005056411016484[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 53 out of 68 | elapsed: 0.2s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 68 out of 68 | elapsed: 0.3s finished [2022-04-12 17:55:50] Features: 4/71 -- score: 0.4174196547714809[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 52 out of 67 | elapsed: 0.2s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 67 out of 67 | elapsed: 0.2s finished [2022-04-12 17:55:51] Features: 5/71 -- score: 0.43222076293523193[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 66 out of 66 | elapsed: 0.2s finished [2022-04-12 17:55:51] Features: 6/71 -- score: 0.44172592802086363[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 65 out of 65 | elapsed: 0.2s finished [2022-04-12 17:55:51] Features: 7/71 -- score: 0.45317074001480134[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 49 out of 64 | elapsed: 0.2s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 64 out of 64 | elapsed: 0.3s finished [2022-04-12 17:55:52] Features: 8/71 -- score: 0.4593783988688152[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 63 out of 63 | elapsed: 0.3s finished [2022-04-12 17:55:52] Features: 9/71 -- score: 0.4652518355617037[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 62 out of 62 | elapsed: 0.3s finished [2022-04-12 17:55:53] Features: 10/71 -- score: 0.4712356970027415[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 46 out of 61 | elapsed: 0.3s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 61 out of 61 | elapsed: 0.4s finished [2022-04-12 17:55:53] Features: 11/71 -- score: 0.4748379884383242[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 45 out of 60 | elapsed: 0.4s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 60 out of 60 | elapsed: 0.5s finished [2022-04-12 17:55:54] Features: 12/71 -- score: 0.4788759723773873[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 59 out of 59 | elapsed: 0.5s finished [2022-04-12 17:55:54] Features: 13/71 -- score: 0.48172194185993045[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.4s [Parallel(n_jobs=-1)]: Done 43 out of 58 | elapsed: 0.4s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 58 out of 58 | elapsed: 0.5s finished [2022-04-12 17:55:55] Features: 14/71 -- score: 0.484668059638815[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.4s [Parallel(n_jobs=-1)]: Done 42 out of 57 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 57 out of 57 | elapsed: 0.6s finished [2022-04-12 17:55:56] Features: 15/71 -- score: 0.48779553232899603[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.5s [Parallel(n_jobs=-1)]: Done 56 out of 56 | elapsed: 0.7s finished [2022-04-12 17:55:56] Features: 16/71 -- score: 0.4896860726135774[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 40 out of 55 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 55 out of 55 | elapsed: 0.6s finished [2022-04-12 17:55:57] Features: 17/71 -- score: 0.49150488345245213[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 54 out of 54 | elapsed: 0.6s finished [2022-04-12 17:55:58] Features: 18/71 -- score: 0.4929449983855525[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 38 out of 53 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 53 out of 53 | elapsed: 0.7s finished [2022-04-12 17:55:59] Features: 19/71 -- score: 0.4947138573328343[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 52 out of 52 | elapsed: 0.7s finished [2022-04-12 17:55:59] Features: 20/71 -- score: 0.49600065751933853[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 36 out of 51 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 51 out of 51 | elapsed: 0.7s finished [2022-04-12 17:56:00] Features: 21/71 -- score: 0.4977994983620356[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 50 out of 50 | elapsed: 0.7s finished [2022-04-12 17:56:01] Features: 22/71 -- score: 0.49899929829971656[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 out of 49 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 49 out of 49 | elapsed: 0.7s finished [2022-04-12 17:56:02] Features: 23/71 -- score: 0.5000700135002234[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 48 out of 48 | elapsed: 0.9s finished [2022-04-12 17:56:03] Features: 24/71 -- score: 0.5013008518232682[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 47 out of 47 | elapsed: 0.7s finished [2022-04-12 17:56:04] Features: 25/71 -- score: 0.5022616354843437[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 46 out of 46 | elapsed: 0.7s finished [2022-04-12 17:56:04] Features: 26/71 -- score: 0.5030824639798428[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 45 | elapsed: 0.6s remaining: 0.3s [Parallel(n_jobs=-1)]: Done 45 out of 45 | elapsed: 0.8s finished [2022-04-12 17:56:05] Features: 27/71 -- score: 0.5038498567527055[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 44 out of 44 | elapsed: 0.8s finished [2022-04-12 17:56:06] Features: 28/71 -- score: 0.5046324131355144[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 43 out of 43 | elapsed: 0.7s finished [2022-04-12 17:56:07] Features: 29/71 -- score: 0.5052024675128335[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 42 out of 42 | elapsed: 0.7s finished [2022-04-12 17:56:08] Features: 30/71 -- score: 0.5055993791428787[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 41 out of 41 | elapsed: 0.8s finished [2022-04-12 17:56:09] Features: 31/71 -- score: 0.5063018797524649[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 out of 40 | elapsed: 0.7s remaining: 0.4s [Parallel(n_jobs=-1)]: Done 40 out of 40 | elapsed: 0.8s finished [2022-04-12 17:56:10] Features: 32/71 -- score: 0.5066930489801373[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 24 out of 39 | elapsed: 0.7s remaining: 0.4s [Parallel(n_jobs=-1)]: Done 39 out of 39 | elapsed: 0.9s finished [2022-04-12 17:56:11] Features: 33/71 -- score: 0.5070901137609963[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 38 out of 38 | elapsed: 0.8s finished [2022-04-12 17:56:12] Features: 34/71 -- score: 0.5073763036837493[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 22 out of 37 | elapsed: 0.6s remaining: 0.4s [Parallel(n_jobs=-1)]: Done 37 out of 37 | elapsed: 0.7s finished [2022-04-12 17:56:12] Features: 35/71 -- score: 0.5076591087988501[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 36 out of 36 | elapsed: 0.8s finished [2022-04-12 17:56:13] Features: 36/71 -- score: 0.5079459351928932[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 35 out of 35 | elapsed: 1.0s finished [2022-04-12 17:56:14] Features: 37/71 -- score: 0.5081872546172406[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 out of 34 | elapsed: 0.9s finished [2022-04-12 17:56:15] Features: 38/71 -- score: 0.508395794079204[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 18 out of 33 | elapsed: 0.7s remaining: 0.6s [Parallel(n_jobs=-1)]: Done 33 out of 33 | elapsed: 0.9s finished [2022-04-12 17:56:16] Features: 39/71 -- score: 0.5086339743081216[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 32 out of 32 | elapsed: 0.8s finished [2022-04-12 17:56:17] Features: 40/71 -- score: 0.5087726457563382[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 31 out of 31 | elapsed: 0.8s finished [2022-04-12 17:56:18] Features: 41/71 -- score: 0.5089607360510882[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 0.7s finished [2022-04-12 17:56:19] Features: 42/71 -- score: 0.5090827109049949[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 29 out of 29 | elapsed: 0.8s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 29 out of 29 | elapsed: 0.8s finished [2022-04-12 17:56:20] Features: 43/71 -- score: 0.5091085185502525[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 28 out of 28 | elapsed: 0.8s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 28 out of 28 | elapsed: 0.8s finished [2022-04-12 17:56:21] Features: 44/71 -- score: 0.5091265928152826[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 27 out of 27 | elapsed: 0.8s finished [2022-04-12 17:56:22] Features: 45/71 -- score: 0.5090907405512923[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 26 out of 26 | elapsed: 0.7s finished [2022-04-12 17:56:22] Features: 46/71 -- score: 0.50906209335144[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 23 out of 25 | elapsed: 0.6s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 25 out of 25 | elapsed: 0.6s finished [2022-04-12 17:56:23] Features: 47/71 -- score: 0.5090304912705245[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 22 out of 24 | elapsed: 0.7s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 24 out of 24 | elapsed: 0.7s finished [2022-04-12 17:56:24] Features: 48/71 -- score: 0.5089922497120654[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 20 out of 23 | elapsed: 0.7s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 23 out of 23 | elapsed: 0.7s finished [2022-04-12 17:56:25] Features: 49/71 -- score: 0.5090922010721937[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 19 out of 22 | elapsed: 0.6s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 22 out of 22 | elapsed: 0.7s finished [2022-04-12 17:56:26] Features: 50/71 -- score: 0.5090371290359708[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 17 out of 21 | elapsed: 0.7s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 21 out of 21 | elapsed: 0.7s finished [2022-04-12 17:56:26] Features: 51/71 -- score: 0.5089610658812349[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 16 out of 20 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 20 out of 20 | elapsed: 0.6s finished [2022-04-12 17:56:27] Features: 52/71 -- score: 0.5088768190842234[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 14 out of 19 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 19 out of 19 | elapsed: 0.6s finished [2022-04-12 17:56:28] Features: 53/71 -- score: 0.5087913729346901[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 13 out of 18 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 18 out of 18 | elapsed: 0.6s finished [2022-04-12 17:56:29] Features: 54/71 -- score: 0.5086628068184877[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 11 out of 17 | elapsed: 0.4s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 17 out of 17 | elapsed: 0.5s finished [2022-04-12 17:56:29] Features: 55/71 -- score: 0.5085185487373822[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 10 out of 16 | elapsed: 0.4s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 16 out of 16 | elapsed: 0.5s finished [2022-04-12 17:56:30] Features: 56/71 -- score: 0.5083562980939954[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 8 out of 15 | elapsed: 0.3s remaining: 0.3s [Parallel(n_jobs=-1)]: Done 15 out of 15 | elapsed: 0.5s finished [2022-04-12 17:56:30] Features: 57/71 -- score: 0.5081893699944808[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 7 out of 14 | elapsed: 0.3s remaining: 0.3s [Parallel(n_jobs=-1)]: Done 14 out of 14 | elapsed: 0.4s finished [2022-04-12 17:56:31] Features: 58/71 -- score: 0.50793955067985[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 5 out of 13 | elapsed: 0.3s remaining: 0.5s [Parallel(n_jobs=-1)]: Done 13 out of 13 | elapsed: 0.4s finished [2022-04-12 17:56:31] Features: 59/71 -- score: 0.5076745579858717[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 4 out of 12 | elapsed: 0.2s remaining: 0.6s [Parallel(n_jobs=-1)]: Done 12 out of 12 | elapsed: 0.4s finished [2022-04-12 17:56:32] Features: 60/71 -- score: 0.5073880804211568[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 2 out of 11 | elapsed: 0.2s remaining: 1.2s [Parallel(n_jobs=-1)]: Done 8 out of 11 | elapsed: 0.3s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 11 out of 11 | elapsed: 0.4s finished [2022-04-12 17:56:32] Features: 61/71 -- score: 0.5070412907695172[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 7 out of 10 | elapsed: 0.3s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 10 out of 10 | elapsed: 0.4s finished [2022-04-12 17:56:33] Features: 62/71 -- score: 0.506680479226362[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 4 out of 9 | elapsed: 0.2s remaining: 0.3s [Parallel(n_jobs=-1)]: Done 9 out of 9 | elapsed: 0.3s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 9 out of 9 | elapsed: 0.3s finished [2022-04-12 17:56:33] Features: 63/71 -- score: 0.5062991320679325[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 3 out of 8 | elapsed: 0.2s remaining: 0.4s [Parallel(n_jobs=-1)]: Done 8 out of 8 | elapsed: 0.3s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 8 out of 8 | elapsed: 0.3s finished [2022-04-12 17:56:34] Features: 64/71 -- score: 0.5059491560394366[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 4 out of 7 | elapsed: 0.2s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 7 out of 7 | elapsed: 0.2s finished [2022-04-12 17:56:34] Features: 65/71 -- score: 0.505542220462096[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 3 out of 6 | elapsed: 0.2s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 6 out of 6 | elapsed: 0.2s finished [2022-04-12 17:56:34] Features: 66/71 -- score: 0.505046141804182[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 2 out of 5 | elapsed: 0.1s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 0.1s finished [2022-04-12 17:56:35] Features: 67/71 -- score: 0.5045388389504056[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 4 out of 4 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 4 out of 4 | elapsed: 0.1s finished [2022-04-12 17:56:35] Features: 68/71 -- score: 0.5040342974289594[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 3 out of 3 | elapsed: 0.1s finished [2022-04-12 17:56:35] Features: 69/71 -- score: 0.503466989481843[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 2 out of 2 | elapsed: 0.1s finished [2022-04-12 17:56:35] Features: 70/71 -- score: 0.5027134493085308[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 1 out of 1 | elapsed: 0.0s finished [2022-04-12 17:56:35] Features: 71/71 -- score: 0.47766875396767494
In [51]:
# to plot the performance with addition of each feature
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
fig1 = plot_sfs(sfs.get_metric_dict(), kind="std_err", figsize=(15, 5))
plt.title("Sequential Forward Selection (w. StdErr)")
plt.xticks(rotation=90)
plt.show()
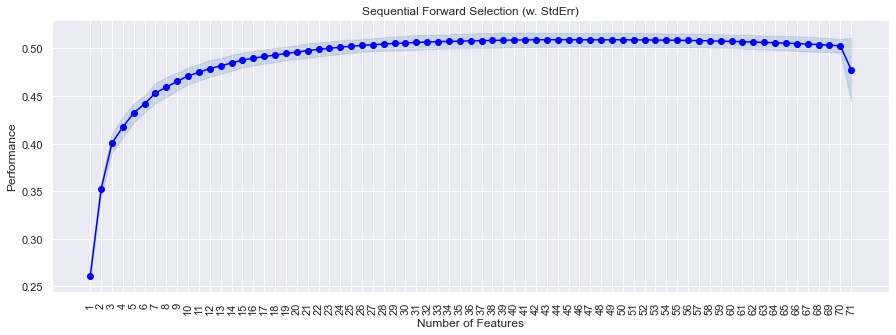
- We can see that performance increases till the 30th feature and then slowly becomes constant, and then drops sharply after the 70th feature is added.
- The decision to choose the k_features now depends on the adjusted R2�2 vs the complexity of the model.
- With 30 features, we are getting an adjusted R2�2 of 0.506
- With 48 features, we are getting an adjusted R2�2 of 0.509.
- With 71 features, we are getting an adjusted R2�2 of 0.477.
- The increase in adjusted R2�2 is not very significant as we are getting the same values with a less complex model.
- So we’ll use 30 features only to build our model, but you can experiment by taking a different number.
- Number of features chosen will also depend on the business context and use case of the model.
In [52]:
reg = LinearRegression()
# Build step forward feature selection
sfs = SFS(
reg,
k_features=30,
forward=True,
floating=False,
scoring="r2",
n_jobs=-1,
verbose=2,
cv=5,
)
# Perform SFFS
sfs = sfs.fit(x_train, y_train)
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.0s [Parallel(n_jobs=-1)]: Done 56 out of 71 | elapsed: 0.0s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 71 out of 71 | elapsed: 0.1s finished [2022-04-12 17:56:37] Features: 1/30 -- score: 0.261089359587903[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.0s [Parallel(n_jobs=-1)]: Done 70 out of 70 | elapsed: 0.1s finished [2022-04-12 17:56:37] Features: 2/30 -- score: 0.3522663085348247[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 54 out of 69 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 69 out of 69 | elapsed: 0.2s finished [2022-04-12 17:56:38] Features: 3/30 -- score: 0.4005056411016484[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 68 out of 68 | elapsed: 0.2s finished [2022-04-12 17:56:38] Features: 4/30 -- score: 0.4174196547714809[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 52 out of 67 | elapsed: 0.2s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 67 out of 67 | elapsed: 0.2s finished [2022-04-12 17:56:38] Features: 5/30 -- score: 0.43222076293523193[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 66 out of 66 | elapsed: 0.2s finished [2022-04-12 17:56:39] Features: 6/30 -- score: 0.44172592802086363[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 50 out of 65 | elapsed: 0.2s remaining: 0.0s [Parallel(n_jobs=-1)]: Done 65 out of 65 | elapsed: 0.3s finished [2022-04-12 17:56:39] Features: 7/30 -- score: 0.45317074001480134[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.1s [Parallel(n_jobs=-1)]: Done 64 out of 64 | elapsed: 0.3s finished [2022-04-12 17:56:39] Features: 8/30 -- score: 0.4593783988688152[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 63 out of 63 | elapsed: 0.3s finished [2022-04-12 17:56:40] Features: 9/30 -- score: 0.4652518355617037[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 62 out of 62 | elapsed: 0.3s finished [2022-04-12 17:56:40] Features: 10/30 -- score: 0.4712356970027415[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.2s [Parallel(n_jobs=-1)]: Done 61 out of 61 | elapsed: 0.4s finished [2022-04-12 17:56:41] Features: 11/30 -- score: 0.4748379884383242[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 60 out of 60 | elapsed: 0.4s finished [2022-04-12 17:56:41] Features: 12/30 -- score: 0.4788759723773873[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 44 out of 59 | elapsed: 0.4s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 59 out of 59 | elapsed: 0.4s finished [2022-04-12 17:56:42] Features: 13/30 -- score: 0.48172194185993045[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 58 out of 58 | elapsed: 0.4s finished [2022-04-12 17:56:42] Features: 14/30 -- score: 0.484668059638815[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.3s [Parallel(n_jobs=-1)]: Done 57 out of 57 | elapsed: 0.4s finished [2022-04-12 17:56:43] Features: 15/30 -- score: 0.48779553232899603[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 0.4s [Parallel(n_jobs=-1)]: Done 41 out of 56 | elapsed: 0.4s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 56 out of 56 | elapsed: 0.5s finished [2022-04-12 17:56:43] Features: 16/30 -- score: 0.4896860726135774[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 40 out of 55 | elapsed: 0.4s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 55 out of 55 | elapsed: 0.5s finished [2022-04-12 17:56:44] Features: 17/30 -- score: 0.49150488345245213[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 54 out of 54 | elapsed: 0.5s finished [2022-04-12 17:56:45] Features: 18/30 -- score: 0.4929449983855525[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 38 out of 53 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 53 out of 53 | elapsed: 0.6s finished [2022-04-12 17:56:45] Features: 19/30 -- score: 0.4947138573328343[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 52 out of 52 | elapsed: 0.6s finished [2022-04-12 17:56:46] Features: 20/30 -- score: 0.49600065751933853[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 36 out of 51 | elapsed: 0.5s remaining: 0.1s [Parallel(n_jobs=-1)]: Done 51 out of 51 | elapsed: 0.6s finished [2022-04-12 17:56:47] Features: 21/30 -- score: 0.4977994983620356[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 50 out of 50 | elapsed: 0.6s finished [2022-04-12 17:56:47] Features: 22/30 -- score: 0.49899929829971656[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 34 out of 49 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 49 out of 49 | elapsed: 0.7s finished [2022-04-12 17:56:48] Features: 23/30 -- score: 0.5000700135002234[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 48 out of 48 | elapsed: 0.7s finished [2022-04-12 17:56:49] Features: 24/30 -- score: 0.5013008518232682[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 32 out of 47 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 47 out of 47 | elapsed: 0.7s finished [2022-04-12 17:56:50] Features: 25/30 -- score: 0.5022616354843437[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 46 out of 46 | elapsed: 0.7s finished [2022-04-12 17:56:51] Features: 26/30 -- score: 0.5030824639798428[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 45 | elapsed: 0.6s remaining: 0.2s [Parallel(n_jobs=-1)]: Done 45 out of 45 | elapsed: 0.8s finished [2022-04-12 17:56:52] Features: 27/30 -- score: 0.5038498567527055[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 44 out of 44 | elapsed: 0.8s finished [2022-04-12 17:56:52] Features: 28/30 -- score: 0.5046324131355144[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 43 out of 43 | elapsed: 0.8s finished [2022-04-12 17:56:53] Features: 29/30 -- score: 0.5052024675128335[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 42 out of 42 | elapsed: 0.9s finished [2022-04-12 17:56:54] Features: 30/30 -- score: 0.5055993791428787
In [53]:
# let us select the features which are important feat_cols = list(sfs.k_feature_idx_) print(feat_cols)
[1, 2, 3, 5, 6, 8, 10, 11, 13, 14, 16, 19, 21, 22, 25, 26, 27, 28, 33, 38, 40, 42, 49, 50, 52, 54, 59, 64, 68, 70]
In [54]:
# let us look at the names of the important features x_train.columns[feat_cols]
Out[54]:
Index(['duration', 'ongoing', 'years_running', 'contentWarn', 'watched',
'wantWatch', 'votes', 'tag_Based_on_a_Manga', 'tag_Action',
'tag_Fantasy', 'tag_Shounen', 'tag_Drama', 'tag_Family_Friendly',
'tag_Short_Episodes', 'tag_Shorts', 'tag_Slice_of_Life', 'tag_Seinen',
'tag_Supernatural', 'tag_Based_on_a_Light_Novel', 'mediaType_Movie',
'mediaType_OVA', 'mediaType_TV', 'sznOfRelease_is_missing',
'studio_primary_AIC', 'studio_primary_DLE', 'studio_primary_J.C. Staff',
'studio_primary_Others', 'studio_primary_Studio Pierrot',
'studio_primary_Toei Animation', 'studio_primary_is_missing'],
dtype='object')
Now we will fit an sklearn model using these features only.
In [55]:
x_train_final = x_train[x_train.columns[feat_cols]]
In [56]:
# Creating new x_test with the same 20 variables that we selected for x_train x_test_final = x_test[x_train_final.columns]
In [57]:
# Fitting linear model lin_reg_model2 = LinearRegression() lin_reg_model2.fit(x_train_final, y_train)
Out[57]:
LinearRegression()
In [58]:
# model performance on train set
print("Training Performance\n")
lin_reg_model2_train_perf = model_performance_regression(
lin_reg_model2, x_train_final, y_train
)
lin_reg_model2_train_perf
Training Performance
Out[58]:
| RMSE | MAE | R-squared | Adj. R-squared | MAPE | |
|---|---|---|---|---|---|
| 0 | 0.582771 | 0.472809 | 0.512392 | 0.509575 | 19.791472 |
In [59]:
# model performance on test set
print("Test Performance\n")
lin_reg_model2_test_perf = model_performance_regression(
lin_reg_model2, x_test_final, y_test
)
lin_reg_model2_test_perf
Test Performance
Out[59]:
| RMSE | MAE | R-squared | Adj. R-squared | MAPE | |
|---|---|---|---|---|---|
| 0 | 0.577022 | 0.470557 | 0.502142 | 0.495381 | 19.67366 |
- The performance looks slightly worse than the previous model.
- Let’s compare the two models we built.
In [60]:
# training performance comparison
models_train_comp_df = pd.concat(
[lin_reg_model_train_perf.T, lin_reg_model2_train_perf.T], axis=1,
)
models_train_comp_df.columns = [
"Linear Regression sklearn",
"Linear Regression sklearn (SFS features)",
]
print("Training performance comparison:")
models_train_comp_df
Training performance comparison:
Out[60]:
| Linear Regression sklearn | Linear Regression sklearn (SFS features) | |
|---|---|---|
| RMSE | 0.577290 | 0.582771 |
| MAE | 0.467123 | 0.472809 |
| R-squared | 0.521520 | 0.512392 |
| Adj. R-squared | 0.514927 | 0.509575 |
| MAPE | 19.550725 | 19.791472 |
In [61]:
# test performance comparison
models_test_comp_df = pd.concat(
[lin_reg_model_test_perf.T, lin_reg_model2_test_perf.T], axis=1,
)
models_test_comp_df.columns = [
"Linear Regression sklearn",
"Linear Regression sklearn (SFS features)",
]
print("Test performance comparison:")
models_test_comp_df
Test performance comparison:
Out[61]:
| Linear Regression sklearn | Linear Regression sklearn (SFS features) | |
|---|---|---|
| RMSE | 0.569001 | 0.577022 |
| MAE | 0.463416 | 0.470557 |
| R-squared | 0.515888 | 0.502142 |
| Adj. R-squared | 0.500034 | 0.495381 |
| MAPE | 19.386434 | 19.673660 |
- The new model (lin_reg_model2) uses less than half the number of features as the previous model (lin_reg_model).
- The performance of the new model, however, is close to our previous model.
- Depending upon time sensitivity and storage restrictions, we can choose between the models.
- We will be moving forward with lin_reg_model as it shows better performance.
Conclusions
- We have been able to build a predictive model that can be used by Streamist to predict the rating of an anime with an R2�2 of 0.52 on the training set.
- Streamist can use this model to predict the anime ratings within a mean error of 0.46
- From the analysis, we found that the duration of each episode, and whether or not an anime is ongoing are some of the factors which tend to increase the rating of an anime. And factors like content warnings tend to decrease the rating of an anime.
- We can also explore improving the linear model by applying non-linear transformations to some of the attributes. This might help us better identify the patterns in the data to predict the anime ratings more accurately.