General Middleware
Prepare for Certified Kubernetes Administrator (CKA)
The CKA serves as a good benchmark for a Kubernetes Administrator. It covers almost all the Kubernetes concepts at a basic to intermediate level. There are various online materials provided by Udemy and other sources, however, it is hard to find a summary of all the topics covered as a one pager. This article will help with an overview of all the topics covered in the exam, along with few scenarios that are very frequently asked in the exam.
kubectl Commands
1. List all pods in default namespace
kubectl get pods
2. List pods in all namespaces
kubectl get pods -A
3. List pods in a particular namespace
kubectl get pods -n=<namespace>
4. Get the current context
kubectl config current-context
You can also view the current config using below command.
kubectl config view
5. Set the current context to use a different namespace
kubectl config set-context --current --namespace=<target_namespace>
6. Get all available namespaces in a cluster
kubectl get ns
7. Create a new namespace in a cluster
kubectl create ns <name>
8. Check the details and events of a Kubernetes object using below command
kubectl get pods -o wide kubectl describe <object_type> <object_name> Example - kubectl describe pod kubemaster-nginx
Example output is given below. It shows complete details of the Kubernetes object along with the lifecycle events.
root@kubemaster:~# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubemaster-nginx 1/1 Running 0 21m 10.36.0.1 kubenode02 <none> <none>
root@kubemaster:~# kubectl describe pod kubemaster-nginx
Name: kubemaster-nginx
Namespace: default
Priority: 0
Service Account: default
Node: kubenode02/192.168.56.4
Start Time: Thu, 22 Sep 2022 23:46:10 +0000
Labels: run=kubemaster-nginx
Annotations: <none>
Status: Running
IP: 10.36.0.1
IPs:
IP: 10.36.0.1
Containers:
kubemaster-nginx:
Container ID: containerd://029346d962ae9b2e819d47b4e926170706da0b524922af2de660cbf2bddde284
Image: nginx
Image ID: docker.io/library/nginx@sha256:0b970013351304af46f322da1263516b188318682b2ab1091862497591189ff1
Port: <none>
Host Port: <none>
State: Running
Started: Thu, 22 Sep 2022 23:54:55 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-fh4qh (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-fh4qh:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned default/kubemaster-nginx to kubenode02
Warning Failed 15m kubelet Failed to pull image "nginx": rpc error: code = Unknown desc = failed to pull and unpack image "docker.io/library/nginx:latest": failed to copy: httpReadSeeker: failed open: failed to do request: Get "https://registry-1.docker.io/v2/library/nginx/blobs/sha256:18f4ffdd25f46fa28f496efb7949b137549b35cb441fb671c1f7fa4e081fd925": net/http: TLS handshake timeout
Warning Failed 14m kubelet Failed to pull image "nginx": rpc error: code = Unknown desc = failed to pull and unpack image "docker.io/library/nginx:latest": failed to copy: httpReadSeeker: failed open: failed to do request: Get "https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/fd/fd42b079d0f818ce0687ee4290715b1b4843a1d5e6ebe7e3144c55ed11a215ca/data?verify=1663893436-YuBCuo6U8CGVV%2Fyqg8dKq3G6lz0%3D": net/http: TLS handshake timeout
Warning Failed 12m (x3 over 15m) kubelet Error: ErrImagePull
Warning Failed 12m kubelet Failed to pull image "nginx": rpc error: code = Unknown desc = failed to pull and unpack image "docker.io/library/nginx:latest": failed to copy: httpReadSeeker: failed open: failed to do request: Get "https://registry-1.docker.io/v2/library/nginx/blobs/sha256:600c24b8ba3900f029e02f62ad9d14a04880ffdf7b8c57bfc74d569477002d67": net/http: TLS handshake timeout
Normal BackOff 12m (x4 over 15m) kubelet Back-off pulling image "nginx"
Warning Failed 12m (x4 over 15m) kubelet Error: ImagePullBackOff
Normal Pulling 12m (x4 over 15m) kubelet Pulling image "nginx"
Normal Pulled 7m3s kubelet Successfully pulled image "nginx" in 5m3.48658924s
Normal Created 7m3s kubelet Created container kubemaster-nginx
Normal Started 7m3s kubelet Started container kubemaster-nginx
9. You can run unix commands in the kubectl command line using $(command) as shown below.
kubectl run $(hostname)-nginx --image=nginx
This will create a pod with name kubemaster-nginx, where the kubemaster is the hostname on which the command is run.
10. Note that resource names e.g. pod, deployment, service etc. should not have underscore (_). The name must consist of lower case alphanumeric characters or ‘-‘, start with an alphabetic character, and end with an alphanumeric character (e.g. ‘my-name’, or ‘abc-123’, regex used for validation is ‘[a-z]([-a-z0-9]*[a-z0-9])?’)
11. Get the system out logs of a running pod.
kubectl logs <pod_name> -f
Note that -f is optional. It is used to tail the logs continuously.
12. Create a deployment with n number of replicas
kubectl create deployment nginx-deployment --image=nginx --replicas=<desired number of replicas>
Note that when a deployment is created with multiple replicas, a replica set is created under the hood.
controlplane $ kubectl create deployment nginx-deployment --image=nginx --replicas=3 deployment.apps/nginx-deployment created controlplane $ kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 16s controlplane $ kubectl get replicaset NAME DESIRED CURRENT READY AGE nginx-deployment-5fbdf85c67 3 3 3 31s
13. Update the deployment with a new image
kubectl set image deployment <deployment-name> <current-container-name>=<new-image> e.g. kubectl set image deployment nginx-deployment nginx=bitnami/nginx
Note that when you do this, a new replica is created, and the cluster slowly brings up Pods in the new replica set, while bringing down Pods in the old replica set. Finally, all the Pods are brought down in the old replica set, and the new replica set is filled with the desired number of active Pods.
controlplane $ kubectl create deployment nginx-deployment --image=nginx --replicas=3 deployment.apps/nginx-deployment created controlplane $ kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 16s controlplane $ kubectl set image deployment nginx-deployment nginx=bitnami/nginx deployment.apps/nginx-deployment image updated controlplane $ kubectl get replicasets NAME DESIRED CURRENT READY AGE nginx-deployment-5fbdf85c67 3 3 3 12m nginx-deployment-c75ddf958 1 1 0 8s controlplane $ kubectl get replicasets NAME DESIRED CURRENT READY AGE nginx-deployment-5fbdf85c67 0 0 0 13m nginx-deployment-c75ddf958 3 3 3 65s
14. How to rollback the current deployment to a previous version.
kubectl rollout undo deployment nginx-deployment
15. Enter into pod
kubectl exec <pod_name> -it -- <command to be run inside the pod>
16. Run commands in a pod and immediately remove it
kubectl run <pod_name> --image=busybox:1.28 --rm --restart=Never -it -- <command to run inside the pod>
17. Create pod, deployment, service
Pod: kubectl run nginx --image=nginx Deployment: kubectl create deployment nginx-deployment --image=nignx --replicas=2 Service: kubectl expose pod nginx --name=service-nginx-pod --port=8080 --target-port=8080 kubectl expose deployment nginx-deployment --name=service-nginx-deployment --port=8080 --target-port=8080
kubectl expose pod nginx –name=new-nginx-svc –port=80 –target-port=80 –type=NodePort
Note: You cannot specify the port number for a NodePort service using imperative commands. This can be done only by modifying the yaml file and using declarative approach. In the imperative approach, which creating a NodePort service, a random port number is picked in the range 30000 – 32767
For NodePort services, you can access the service from outside the cluster using any of the cluster nodes as target host.
For Cluster IP services, you can access only from within the cluster.
18. Replace existing object forcefully
Sometimes, you need to replace the existing objects using force. This is applicable, when an old object has to be deleted before creating a new one. For example, while updating the name of a service.
Here is the command for the same.
kubectl replace --force -f <yaml file>
19. Increase/Decrease replicas of deployment
kubectl scale deployment nginx-deployment --replicas=5
20. Record step in annotation
Use the –record option at the end of any command to record the step in the object annotation
Accessibility of Kubernetes Resources
1. How can you access an application deployed in Kubernetes ?
Note that even after deploying your application as Pods, Replica Sets or Deployments, the application cannot be accessed in the form of an URL. In order to do that, you need to either expose your Pod or Deployment as a Service or create a new Service and link it to the target Pod or Deployment using selectors.
Expose a Pod or Deployment as a Service
kubectl expose pod <pod_name> --name=<service_name> --target-port=<application_port_on_the_pod> --port=<service_port> kubectl expose deployment <deployment_name> --name=<service_name> --target-port=<application_port_on_the_deployment_pod> --port=<service_port>
Create a new Service and link it to a Pod
a. First, create the service, specifying
kubectl create service <clusterip|nodeport> <service_name> --tcp=<service_port>:<target_port>
Above command will just create the service and specify the service and the target ports, but it does not have the target Endpoint (highlighted in bold below). Look at how the object looks like at this stage.
Name: nginx-moumita-svc-1 Namespace: moumita Labels: app=nginx-moumita-svc-1 Annotations: <none> Selector: app=nginx-moumita-svc-1 Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.107.88.11 IPs: 10.107.88.11 Port: 80-80 80/TCP TargetPort: 80/TCP Endpoints: <none> Session Affinity: None Events: <none>
At this stage, the service is still not functional, since there is no Endpoint.
b. Now, edit the service to update the selector, to match with the target pod Lebel, and that will automatically update the Endpoint.
kubectl edit svc <service_name>
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2022-09-24T06:01:19Z"
labels:
app: nginx-moumita-svc-1
name: nginx-moumita-svc-1
namespace: moumita
resourceVersion: "30726"
uid: 71de2523-9060-4b7b-9d0a-6e653ea00c63
spec:
clusterIP: 10.107.88.11
clusterIPs:
- 10.107.88.11
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: 80-80
port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx-moumita
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Update the highlighted selector to match the Pod Label.
c. Then, you can find that the Endpoint has been updated in the service.
Name: nginx-moumita-svc-1 Namespace: moumita Labels: app=nginx-moumita-svc-1 Annotations: <none> Selector: run=nginx-moumita Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.107.88.11 IPs: 10.107.88.11 Port: 80-80 80/TCP TargetPort: 80/TCP Endpoints: 10.44.0.3:80 Session Affinity: None Events: <none>
d. Now, you can access the application using the service name
- If you want to access the service from a different namespace, use the fully qualified name as shown below.
curl http://<service_name>.<namespace_where_the_service_is_present>.svc.cluster.local:<service_port>/
- In case, you want to access the service from a Pod in the same namespace, just using the service name is fine.
curl http://<service_name>:<service_port>/
Note that whenever a new Pod is created, below file is created for DNS resolution inside the Pod.
# cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5
The highlighted search field in resolv.conf is responsible for appending the suffix to the provided name in URL to form the complete DNS. For example, if the service is called with URL http://<service_name>:<port>/, then the DNS service appends default.svc.cluster.local to form the complete DNS (http://<service_name>.default.svc.cluster.local:<port>/), and as you know, it looks up the resource in the default namespace. On the other hand, to reach a service in another namespace, use the URL http://<service_name>.<namespace>:<port>/. In this case, the DNS service appends svc.cluster.local to form the complete DNS (http://<service_name>.<namespace>.svc.cluster.local:<port>/).
Access the Kubernetes Cluster
You can access the cluster either with a Normal User or with a Service Account. The way they are created are different. Ideally, there is no object called User in K8S. Rather, you create a certificate with the Username defined in the CN of the certificate. Look at the below steps to create a User for cluster access in K8S.
The permission level given to an user is set in the Organization of the Certificate Subject DN. An admin client certificate should have the Organization specified as system:masters as below. system:masters is a group which is hardcoded into the Kubernetes API server source code as having unrestricted rights to the Kubernetes API server.
Subject: O=system:masters, CN=kubernetes-admin
In addition, it should be issued by the Kubernetes Cluster CA. See how it looks like.
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 405133203608144971 (0x59f52808fc78c4b)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes
Validity
Not Before: Sep 22 02:11:17 2022 GMT
Not After : Sep 22 02:11:18 2023 GMT
Subject: O=system:masters, CN=kubernetes-admin
Below are the steps to create a new certificate for a new admins.
i. Create key/cert pair using openssl
openssl req -nodes -newkey rsa:2048 -sha256 -nodes -keyout mykey.middlewareworld.org.key -out mykey.middlewareworld.org.csr -subj "/C=US/ST=Texas/L=Austin/O=system:masters/OU=Middleware/CN=middlewareworld.org"
ii. Create a CertificateSigningRequest object in the K8S Cluster
cat <<EOF | kubectl apply -f - apiVersion: certificates.k8s.io/v1 kind: CertificateSigningRequest metadata: name: myuser spec: request: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0KTUlJQ1ZqQ0NBVDRDQVFBd0VURVBNQTBHQTFVRUF3d0dZVzVuWld4aE1JSUJJakFOQmdrcWhraUc5dzBCQVFFRgpBQU9DQVE4QU1JSUJDZ0tDQVFFQTByczhJTHRHdTYxakx2dHhWTTJSVlRWMDNHWlJTWWw0dWluVWo4RElaWjBOCnR2MUZtRVFSd3VoaUZsOFEzcWl0Qm0wMUFSMkNJVXBGd2ZzSjZ4MXF3ckJzVkhZbGlBNVhwRVpZM3ExcGswSDQKM3Z3aGJlK1o2MVNrVHF5SVBYUUwrTWM5T1Nsbm0xb0R2N0NtSkZNMUlMRVI3QTVGZnZKOEdFRjJ6dHBoaUlFMwpub1dtdHNZb3JuT2wzc2lHQ2ZGZzR4Zmd4eW8ybmlneFNVekl1bXNnVm9PM2ttT0x1RVF6cXpkakJ3TFJXbWlECklmMXBMWnoyalVnald4UkhCM1gyWnVVV1d1T09PZnpXM01LaE8ybHEvZi9DdS8wYk83c0x0MCt3U2ZMSU91TFcKcW90blZtRmxMMytqTy82WDNDKzBERHk5aUtwbXJjVDBnWGZLemE1dHJRSURBUUFCb0FBd0RRWUpLb1pJaHZjTgpBUUVMQlFBRGdnRUJBR05WdmVIOGR4ZzNvK21VeVRkbmFjVmQ1N24zSkExdnZEU1JWREkyQTZ1eXN3ZFp1L1BVCkkwZXpZWFV0RVNnSk1IRmQycVVNMjNuNVJsSXJ3R0xuUXFISUh5VStWWHhsdnZsRnpNOVpEWllSTmU3QlJvYXgKQVlEdUI5STZXT3FYbkFvczFqRmxNUG5NbFpqdU5kSGxpT1BjTU1oNndLaTZzZFhpVStHYTJ2RUVLY01jSVUyRgpvU2djUWdMYTk0aEpacGk3ZnNMdm1OQUxoT045UHdNMGM1dVJVejV4T0dGMUtCbWRSeEgvbUNOS2JKYjFRQm1HCkkwYitEUEdaTktXTU0xMzhIQXdoV0tkNjVoVHdYOWl4V3ZHMkh4TG1WQzg0L1BHT0tWQW9FNkpsYWFHdTlQVmkKdjlOSjVaZlZrcXdCd0hKbzZXdk9xVlA3SVFjZmg3d0drWm89Ci0tLS0tRU5EIENFUlRJRklDQVRFIFJFUVVFU1QtLS0tLQo= signerName: kubernetes.io/kube-apiserver-client expirationSeconds: 86400 # one day usages: - client auth EOF
iii. Approve the CSR
kubectl certificate approve myuser
iv. Get the signed certificate from the CSR object
v. Once you have the signed certificate along with the private key, use the KUBECONFIG to pass the client certs along with the target cluster to connect. KUBECONFIG is a yaml file that is read by kubectl utility to extract the client certs and the target cluster to connect. See how the config file will look like.
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1Ea3lNakF5TVRFeE4xb1hEVE15TURreE9UQXlNVEV4TjFvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBUENlCm1DSFBaa2VxdytRQm94ZGNiSTNKd2pSYmxLc09CZUJHaDd6ckdZYWY5SzVWZUhkWDBKdU9mT05WQ0hhVkxmSzcKNENad0xUSHFvWTFCTGkxYk93Unk0WlREOTV3NGI3eDF6ZDJmbHdGVkNaN2ZpMXhtNnd3Z2tjUWZVQy9jdVAvbgo5NTA4RzRNaWZvakxhV3JsTDN0bk5wRlBnWFdyUmFEQjBhWHlJWjNNMHNnVDVPQ0g5dkl1MnNpQlE0Z3FiTXd4CkF4dWNVS1JBUDVDRWZOUm1uWk44ZDRaTnVGT1ByZGpac0srK0xaY0JrK1BybkkraUZ3QU1BcmhlZlVXbkVYNk0KQjg2OXdFbVhNWkRFbkNycVVaeS91NUpoOCtpNmhHa1o3REpIdWNYSmlndW9Pa0g4QzYrTEtZcEdiVGtIaDBZeQpwMWhLL0dpd1VaZmFRQWYwMHdrQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZOM2lONFJvYWY4MXZIcUdhM0ZvSTBZQlEvbXRNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBT1VQUmRPUlBQWC9JZzBmaHJ4UgoxZU8velVmSUkxMGdpbm1maE85U2ppZE9SL0d6TVBiL0xoQTU0Z0dham1heEV1WFBlQXNWUWdVT0xlOWxqU1RSCkVwWUtrQnBjK1F1ckN3OC9jcGh3S2pxdlhsb1hVcVRMdWpNV21WZmdVU2dhWFJSRzhaV3pNVkZpdmplRDVJYXkKRHBmR2FUS3NtMmo2amRCSmc5UDlwaDNNalVHYUZ2czJKR1RtanhyUWJWeGxWeTI3NWZrTElsVkYvYWJOSVZZdwpsTEFKS1cwTWhITGxzVlY1bW02NzkzNWQvMmdOUklGVjlRQXZGS2VoQ3k1MjlmZ3NaRnRuTzNwRWF0bFdUZEQ0CkN2cXgwVUsxblpaRWpHc2d0eTZocEkzUGFtbzB4TEl1SkZ4Q0xFd09RaU9PUUJPWUFRM3R4eW5DUW55VHNWQngKd09zPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
server: https://192.168.56.2:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURJVENDQWdtZ0F3SUJBZ0lJQlo5U2dJL0hqRXN3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TWpBNU1qSXdNakV4TVRkYUZ3MHlNekE1TWpJd01qRXhNVGhhTURReApGekFWQmdOVkJBb1REbk41YzNSbGJUcHRZWE4wWlhKek1Sa3dGd1lEVlFRREV4QnJkV0psY201bGRHVnpMV0ZrCmJXbHVNSUlCSWpBTkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUJDZ0tDQVFFQThYZjlnbk1vQWplQkRKeHgKQ3Q5M2NEQk1hUzV3Qm5yYmF5UDJuUGtRbVlyOTk3WVNtQkZ0UGs1ZmlXTFZiNzRzYUkzUGxNZmdTQkJJbkg1agpCdlJTUzlSTE1abWp1U2pKcVQwazZCMk9ycjRvWWxHc25pSERPdUFlRnpPcXBOY3FCOVl6R01Wa3hkTG92S1RPCnFlQUlVZWdROFJVNXMyb3lQTTVxUlQ0Q2RaWjdHTi9CMm9TQkRFbi9WcDVnYlFSWDBuaWJKTmdFVGJOTXVNZ1cKQVpmMVczV3hHZlYxWEQ5SStzcCs2UVdhOUxCQ1dIZXFmVi9MbHBpbytPTGNJTVBCdFpmUUhMUWhCZWhMTVNONQpyVEl2QkZIYllvenRYdTZUNEdOTGtsa2xzNE5hMnJDNlVoSy9XaURxZWkzM0lGZFBTOXJUQUVrVGdVVVVyN2lCCmJBUkoxUUlEQVFBQm8xWXdWREFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0RBWURWUjBUQVFIL0JBSXdBREFmQmdOVkhTTUVHREFXZ0JUZDRqZUVhR24vTmJ4NmhtdHhhQ05HQVVQNQpyVEFOQmdrcWhraUc5dzBCQVFzRkFBT0NBUUVBenozdGFnQ21UOWZkOStWN1didDJwVGs2T29BYjY3N09pRWRTCjhvK0syR0MrRlc2SE5Yc1Zxc0FUMVlqWkI1MDZCeDZidThTNFVVbHhGQ3RJaitYZC94d2JTd1hLeE1xOG95OG8KcjQ5bzBuSm1wUTVCU1BQeHYwVkFSNjhqMENHbjFZQnpqSnpKd2c3YUdCdVdJOGd2QjhzUkZaakwxVGhtSnlncApqTVM0T1dPL1Jwd3JxOVpscU5RckZ5cTVzdXZ2NW9BQ29CNnQ3Z1BRYUNSWDVqWlYxaTh0ZGJrREtMT2kzOTR1CnJJNldkYmYvaVJlZVM2a2tZdXluai81bUhGZlliRVpjRnNjNWtqRExkM3l1cmE4YUFzQ2ZlMVhzU1ExbHIwcVMKYlphbWE3eFpGc3BqWTVTajlmczMxRHRjbzFCZTFwRkZLMHMyL3Z5WlNYNDJvTU02SXc9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcFFJQkFBS0NBUUVBOFhmOWduTW9BamVCREp4eEN0OTNjREJNYVM1d0JucmJheVAyblBrUW1Zcjk5N1lTCm1CRnRQazVmaVdMVmI3NHNhSTNQbE1mZ1NCQkluSDVqQnZSU1M5UkxNWm1qdVNqSnFUMGs2QjJPcnI0b1lsR3MKbmlIRE91QWVGek9xcE5jcUI5WXpHTVZreGRMb3ZLVE9xZUFJVWVnUThSVTVzMm95UE01cVJUNENkWlo3R04vQgoyb1NCREVuL1ZwNWdiUVJYMG5pYkpOZ0VUYk5NdU1nV0FaZjFXM1d4R2ZWMVhEOUkrc3ArNlFXYTlMQkNXSGVxCmZWL0xscGlvK09MY0lNUEJ0WmZRSExRaEJlaExNU041clRJdkJGSGJZb3p0WHU2VDRHTkxrbGtsczROYTJyQzYKVWhLL1dpRHFlaTMzSUZkUFM5clRBRWtUZ1VVVXI3aUJiQVJKMVFJREFRQUJBb0lCQVFEYnVDVnp1RGxsbXYvUQphK0hvMU9LbnNTczJZazBKZUcyRUZsdG5Cck4ySTZWbzY4SUxvWC9ZUEJSdXZRSWVCZHYrMzF0TnRIcCsyR0phCkZCOGp5dG0vcWxNcHRQWG5uQmV6NmJGVmpOK3lYZEg5ZFBndmcrVlVBMjhlQ2FOekQxNXRkeGxUcHZwRmo5NjcKR1BQOFc2RDJkc1pEdU42aVJUV2xZdVlNVDVxSlJ6bjE4azlDemJ0WVdiZUc3SnhWd2lnQWRBSldxVjFxV29NVAplSWpIWUNFbWRFczFNSkFBMVRqekJESlN0dVpWYzZ3QUdFRFdmOVM1eXhaS2hIeTVkQjJKcXh3RUxHdkQxL1dHCkVPaDNaUmE0TCtoU1RQMU40UE8wNUlUdkpING15dXRGUEJWdnQ5dUNZbTl1dEJ2STQ4NE9CRVc0dXMrQldnWEoKSER0dXFpWUJBb0dCQVAzQ3E1M012Y0hrYmJHR21uQ1M5OTZ1WUU2OUQyV1ZGNmZCOTdpSi9kTGRaUk1NUi9iTApyVWhSaUxHU1YrbFpXbGpodXA4S0ZDT1ZtTWVRYUFYczhGTDFwTWRBUmcya3U1Y1NKeEJUdHRXdG5DdzVDVzlhCmdGaENUTHBiNzJLaU81NW0xTGUzTy9OeDdvK1FmTE01WFMzUCtLcXUrSU5xNHIxQ3JMQVVoSnZCQW9HQkFQT1oKakgyOFBnS1daWi9QMTlPbGFGdkVSUkhMNXlJZU0vVVBiQmR4UzlrWE9rczZ0Zkk1c2VRTmRMV253YlBhejBnbwpGVzQ1eHVwK1JBckVaU0trS0YzamJtbWQwQU5iaHNNRVlyZHRPT2RaY2lObk5IUTFiWmxzOWJPdmhGaXEvRXNUCjRmQ2s5dkhZb1l5bEhKNXF4UGorbHorU2Ixdlh2SHlONVI2Z1lFTVZBb0dCQUozVHl4dHRNUVI4QjRHbm56eXYKRy8xaTVVRnpzelRTQXhGeXdaa0VNbHRKR2NrOEZUSTVRY0E5L2MrN25uUGpBQjlSM2RsMjBrbkRqRzlxc0ZnbgpJdDNtTENORkpZenN6VVBMcFlJeEh3Rk5abG5XNjdoWFNJWWNUazZHU2FCR0dPQ1BRblExUWROTEpENGtkbnFlCkRnY2xWNXNKRWtYaVg3Mm96M0VBZ2UzQkFvR0JBSmh0REN2aERpd3dUNGFnVnp4bjA5VVlDdUFINXFqQ25XQksKTmlpMUMvRGJSKzZxM2c2amExeDN6ditiNk9qUmtjSmswb1FXUXhHWDBKdXNLRngwdTQyRU1pS0VUUlRNd0pabQp1QjV1aVp5NXEySGJ3a2EwNTgrSkRuVlE3azlOTG5FTUQrUzBWSkVnTEhZRkd0TkZtOXJ4ODFJa0h1b3BKQmdMCjhjSW9PQlBCQW9HQVhrUEYrSjlnSlpQcytxcFcvdGkxd2NnWTlkWDNDbTRyNTBSbmhrR1VrUnhiZlpjSFVZT0wKengvVE1yb2ZDVk02ZDNvbG1WZldSSkU3TlFTRlRBVTluWkdGUWdETU56RzNPUDl6ZHVQSW52RHF6TVBQTmxvaQpWWndhWFRlYWdFQmt4U0c1aTIxam55VlJpMm5WK1BtQ1ptb1Eva3ArcG01Q0t0SjRpaWVoYk84PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
vi. The above KUBECONFIG can be passed in the command line as below.
kubectl get pods --kubeconfig <path to the kubeconfig file>
Another option is to place the file in the below path
<current user's home>/.kube/config
Note: The above steps are specifically to create an admin user, by specifying the O=system:masters in the Subject DN of the certificate. However, if you want to create a normal user, just create a certificate with any Subject DN, and bind that user with the respective Role and RoleBinding or ClusterRole and ClusterRoleBinding as explained below.
Creating Roles and RoleBindings
To access any objects in a K8S cluster using any of the clients (kubectl or direct API Calls), you need to ensure that the user has access. A crude way of maintaining access is to provide access to each users individually. However, a better approach is to creates roles, defining the permission sets, and role bindings to link the users to the roles.
Roles and RoleBindings are used to provide access to certain namespaces.
1. Create a Role to define the access permissions in a particular namespace
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: default name: pod-reader rules: - apiGroups: [""] # "" indicates the core API group resources: ["pods"] verbs: ["get", "watch", "list"]
2. Create a RoleBinding to link an user to a specific Role in the same namespace
apiVersion: rbac.authorization.k8s.io/v1 # This role binding allows "jane" to read pods in the "default" namespace. # You need to already have a Role named "pod-reader" in that namespace. kind: RoleBinding metadata: name: read-pods namespace: default subjects: # You can specify more than one "subject" - kind: User name: jane # "name" is case sensitive apiGroup: rbac.authorization.k8s.io roleRef: # "roleRef" specifies the binding to a Role / ClusterRole kind: Role #this must be Role or ClusterRole name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to apiGroup: rbac.authorization.k8s.io
Creating ClusterRoles and ClusterRoleBindings
These are used to provide cluster wide access, across all namespaces
1. Create a ClusterRole
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: # "namespace" omitted since ClusterRoles are not namespaced name: secret-reader rules: - apiGroups: [""] # # at the HTTP level, the name of the resource for accessing Secret # objects is "secrets" resources: ["secrets"] verbs: ["get", "watch", "list"]
2. Create a ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1 # This cluster role binding allows anyone in the "manager" group to read secrets in any namespace. kind: ClusterRoleBinding metadata: name: read-secrets-global subjects: - kind: Group name: manager # Name is case sensitive apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: secret-reader apiGroup: rbac.authorization.k8s.io
Service Accounts
Service Accounts are used to provide access to the kubernetes cluster from systems e.g. Jenkins, Ansible, Chef or other automation platforms. All such accounts should not have the same level of access. For example, for development automation, a job might just need access to few resources in the “dev” namespace and for production automation, the job might need access to resources in the “prod” namespace. There are few steps we need to follow to provide the right level of access to a Service Account.
1. First, we need to define the level of access required. Let’s consider listing pods for this example.
2. Create a Service Account
kubectl create sa animbane # animbane is the name of the account
3. Create a token for the Service Account. Note that from Kubernetes v1.24, there has been a big change in the way how service accounts are linked to the secrets. Previously, a token secret was automatically created and attached to a Service Account. However, from v1.24, the token has to be created separately.
export TOKEN=`kubectl create token animbane`
4. Create a ClusterRole (or Role) defining the level of access required, by specifically mentioning the resources and verbs.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
name: animbane-cr
rules:
- apiGroups:
- ""
resources: ["pods"]
verbs: ["get", "list"]
5. Create a ClusterRoleBinding (or RoleBinding) to link the service account (animbane) with the ClusterRole created in Step 4.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
name: animbane-crb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: animbane-cr
subjects:
- kind: ServiceAccount
name: animbane
namespace: default
6. Now try to access the cluster
export APISERVER=`kubectl config view -o jsonpath='{.clusters[0].cluster.server}'`
curl -k --header "Authorization: Bearer $TOKEN" $APISERVER/api/v1/pods
Image Security
Till now, we have always mentioned the image directly in the Pod definition files. However, in case it is a restricted image and you need to pass credentials to the registry, a new regcred secret needs to be created and referred by the Pod.
1. Create the docker registry secret
kubectl create secret docker-registry anbanerj11 --docker-username=<user> --docker-password=<password> --docker-email=<email>
2. Refer to the secret in your Pod.
apiVersion: v1
kind: Pod
metadata:
labels:
run: anbanerj11
name: tomcat-custom
spec:
containers:
- image: anbanerjreg/tomcat_custom:v10
name: tomcat-custom
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
imagePullSecrets:
- name: anbanerj11
status: {}
Note how the secret name (anbanerj11) is referred in the Pod using the imagePullSecrets and how the image name is referred to with the right registry name (anbanerjreg).
How to override docker image ENTRYPOINT and CMD in Pods
In docker images, the ENTRYPOINT is the primary command that is run inside the container and the CMD defines the arguments to the ENTRYPOINT, if the latter is present. However, if the ENTRYPOINT is not present, then the CMD is considered as the primary command to execute at runtime.
While referring to the docker image in a Pod, it is possible to override either or both of the ENTRYPOINT and CMD specified in the docker image.
In Pods, command replaces ENTRYPOINT instructions and args replaces CMD instructions. Look at the below Pod definition file that replaces the ENTRYPOINT and CMD combination in the docker image (tomcat) to the new values specified in the Pod.
apiVersion: v1
kind: Pod
metadata:
name: tomcat-custom-args-cmd
spec:
containers:
- image: tomcat
name: tomcat-custom-args-cmd
args: ["100000000"] #This overrides CMD
command: ["sleep"] #This overrides ENTRYPOINT
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
The final executable command from the tomcat image is “./catalina.sh run“. However, the Pod will ignore that and will execute “sleep 100000000“
Kube Proxy
Kube proxy is a service that can be started using kubectl. It serves as a proxy to connect to the Kubernetes cluster using the APIs. Without the proxy, you need to have a proper Authorization for direct connection. However, with the proxy running, you can access the cluster APIs without any credentials. The proxy uses the Kubernetes default credentials to establish the connection and fetch the desired results.
This is how you can start the Kube Proxy
kubectl proxy Starting to serve on 127.0.0.1:8001
One the proxy is started, just connect to the proxy to get any data from the cluster without providing credentials.
curl -k https://localhost:8001/api/v1/pods curl -k https://localhost:8001/api/v1/nodes
However, check that you cannot access the cluster directly, without credentials.
curl -k https://192.168.56.2:6443/api/v1/pods
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "pods is forbidden: User \"system:anonymous\" cannot list resource \"pods\" in API group \"\" at the cluster scope",
"reason": "Forbidden",
"details": {
"kind": "pods"
},
"code": 403
Accessing the Cluster APIs directly
In contrast to accessing the cluster APIs through the Kube Proxy, if you want to directly access the same APIs, a secret token is required. It can then be used as a Bearer token for Authentication.
Let’s create the secret first.
apiVersion: v1
kind: Secret
metadata:
name: myserviceaccounttoken
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
Note that there are different type of secrets that can be create as mentioned here.
For API access, the type of secret should be kubernetes.io/service-account-token. Once the Secret is created, extract the token using below command.
export TOKEN=`kubectl get secret myserviceaccounttoken -o jsonpath='{.data.token}' | base64 --decode`
Now use the decoded token to call the APIs.
export APIServer=`kubectl config view -o jsonpath='{.clusters[0].cluster.server}'`
curl -k --header "Authorization: Bearer ${TOKEN}" ${APIServer}/api
Create a Pod with labels and environment variables
kubectl run nginx –image=niginx –labels=app=frontend,role=webserver –env=environment=production –env=tested=true
Using Config Map variables in Pods
In order to test this, we have to go through a few steps. Let’s use a custom tomcat image to translate the environment variable to its configuration.
1. Custom image for tomcat, that uses an environment variable for the listen port.
FROM tomcat AS stage FROM openjdk:11 RUN mkdir /usr/local/tomcat COPY --chown=root:root --from=stage /usr/local/tomcat /usr/local/tomcat WORKDIR /usr/local/tomcat/conf COPY --chown=root:root ./server.xml . WORKDIR /usr/local/tomcat/bin CMD [ "run" ] ENTRYPOINT [ "./catalina.sh" ]
Refer to below server.xml which is referred by the above Dockerfile
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="${tomcatport}" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>
Look at the tomcatport variable referred to in the server.xml.
2. Now, let’s create the docker image and push it to dockerhub
docker build . -t <dockerhub account id>/tomcat_custom:v10 docker push <dockerhub account id>/tomcat_custom:v10
3. Let’s now create the config map that contains the desired value of the environment variable.
kubectl create cm tomcat-cmap --from-literal=JAVA_OPTS=-Dtomcatport=9998
Note that JAVA_OPTS is a standard variable that is defined in the Catalina.sh of tomcat, which helps to insert the system variable tomcatport, which in turn, is used in the server.xml
4. Now, create the Pod definition file
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
app: tomcat-cm
name: tomcat-cm
spec:
containers:
- image: anbanerj11/tomcat_custom:v10
imagePullPolicy: IfNotPresent
name: tomcat-cm
env:
- name: JAVA_OPTS
valueFrom:
configMapKeyRef:
name: nginx-cmap
key: JAVA_OPTS
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
5. Once the pod is created from the above definition file, you see that it is listening on port 9998, which is defined in the config map.
Mount ConfigMap as Volumes in Pods
ConfigMaps can be mounted as volumes in Pods. It will create certain files inside the Pod which can be referred by the Pod. Primarily, there are two types.
1. ConfigMaps created from files
a. Use the below steps to create a configmap from a properties file
Properties File
bash-3.2$ cat data.txt
name=animesh
location=singapore
address=woodlands
Create the configmap
bash-3.2$ k create configmap fileconfig –from-file=data.txt
configmap/fileconfig created
View the Configmap object
bash-3.2$ k describe cm fileconfig
Name: fileconfig
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
data.txt:
—-
name=animesh
location=singapore
address=woodlands
company=visa
BinaryData
====
Events: <none>
bash-3.2$ cat data.txt
name=animesh
location=singapore
address=woodlands
b. Mount the configmap as volume inside a Pod.
Pod definition file
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
– name: test-container
image: registry.k8s.io/busybox
command: [ “sleep”, “1000000000” ]
volumeMounts:
– name: config-volume
mountPath: /etc/config
volumes:
– name: config-volume
configMap:
# Provide the name of the ConfigMap containing the files you want
# to add to the container
name: fileconfig
restartPolicy: Never
Once Pod is created, exec into the Pod and look at how the data.txt has been created as a file under /etc/config with the key/value pairs as contents of the file.
bash-3.2$ k exec -it dapi-test-pod -- /bin/sh / # pd /bin/sh: pd: not found / # cd /etc/config /etc/config # ls -lrt total 0 lrwxrwxrwx 1 root root 15 Oct 23 00:46 data.txt -> ..data/data.txt /etc/config # cat data.txt name=animesh location=singapore address=woodlands
Basically, when you mount a configmap as volume, all the keys will be created as files in the Pod, and the values as the file contents. In the above case, look at the configmap description and you will find that the properties filename (data.txt) has been created as the Key in the config map. That’s why it is created as a file under /etc/config.
bash-3.2$ k describe cm fileconfig Name: fileconfig Namespace: default Labels: <none> Annotations: <none> Data ==== data.txt: ---- name=animesh location=singapore address=woodlands company=visa BinaryData ==== Events: <none> bash-3.2$ cat data.txt name=animesh location=singapore address=woodlands
2. ConfigMaps with regular key/value pairs
The same concept mentioned above applies for configmaps with regular key/value pairs. In this case, each key will be a new file with the respective value as the contents of the file.
a. Create the configmap
Config Map definition file
apiVersion: v1
kind: ConfigMap
metadata:
name: animeshconfig
namespace: default
data:
name: animesh
location: singapore
b. View the contents of the configmap
kubectl describe cm animeshconfig
Name: animeshconfig
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
location:
—-
singapore
name:
—-
animesh
BinaryData
====
Events: <none>
Looking at the above configmap, we see that there are 2 keys – location and name. So, when this is mounted as volume, two files named location and name should be created in the specified path inside the Pod.
c. Create the Pod and Mount the configmap
Pod definition file
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod2
spec:
containers:
– name: test-container
image: registry.k8s.io/busybox
command: [ “sleep”, “1000000000” ]
volumeMounts:
– name: config-volume
mountPath: /var/mount/
volumes:
– name: config-volume
configMap:
# Provide the name of the ConfigMap containing the files you want
# to add to the container
name: animeshconfig
restartPolicy: Never
d. Now check the /var/mount inside the Pod.
bash-3.2$ k exec -it dapi-test-pod2 -- /bin/sh / # cd /var/mount /var/mount # ls -lrt total 0 lrwxrwxrwx 1 root root 11 Oct 23 01:07 name -> ..data/name lrwxrwxrwx 1 root root 15 Oct 23 01:07 location -> ..data/location /var/mount # cat name animesh /var/mount # cat location singapore /var/mount #
How configmaps are used by the kube-system Pods
The kube-system Pods are the ones that form the cluster. Many of them mount configmaps as volumes. Look at all the configmaps in the kube-system namespace.
bash-3.2$ kubectl get cm -n kube-system -o wide NAME DATA AGE coredns 1 30d extension-apiserver-authentication 6 30d kube-proxy 2 30d kube-root-ca.crt 1 30d kubeadm-config 1 30d kubelet-config 1 30d weave-net 0 30d
From the names, we understand that codedns, apiserver, kube-proxy, kubelet and weave-net uses the configmaps. Let’s look at the the kube-proxy to see how it is being used. Note that kube-proxy and weave-net are deployed as daemonsets.
bash-3.2$ k get ds kube-proxy -n kube-system -o yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
annotations:
deprecated.daemonset.template.generation: "1"
creationTimestamp: "2022-09-22T02:11:31Z"
generation: 1
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: kube-system
resourceVersion: "216034"
uid: 67ac59c9-1985-4a67-ac37-01d116f17c6d
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kube-proxy
template:
metadata:
creationTimestamp: null
labels:
k8s-app: kube-proxy
spec:
containers:
- command:
- /usr/local/bin/kube-proxy
- --config=/var/lib/kube-proxy/config.conf
- --hostname-override=$(NODE_NAME)
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: registry.k8s.io/kube-proxy:v1.25.2
imagePullPolicy: IfNotPresent
name: kube-proxy
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/kube-proxy
name: kube-proxy
- mountPath: /run/xtables.lock
name: xtables-lock
- mountPath: /lib/modules
name: lib-modules
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kube-proxy
serviceAccountName: kube-proxy
terminationGracePeriodSeconds: 30
tolerations:
- operator: Exists
volumes:
- configMap:
defaultMode: 420
name: kube-proxy
name: kube-proxy
- hostPath:
path: /run/xtables.lock
type: FileOrCreate
name: xtables-lock
- hostPath:
path: /lib/modules
type: ""
name: lib-modules
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
status:
currentNumberScheduled: 3
desiredNumberScheduled: 3
numberAvailable: 3
numberMisscheduled: 0
numberReady: 3
observedGeneration: 1
updatedNumberScheduled: 3
Working with node affinity to control Pod scheduling
Pods get scheduled in a cluster node randomly. However, there are few ways to control this.
1. Using taints and tolerations
Taints are added to a node and tolerations are added to pods. A Pod can be scheduled in a node with certain taints, only if it is tolerant to that taint in the node.
Use the below command to add taint to a node.
kubectl taint nodes <nodename> <key>=<value>:<taint effect> e.g. kubectl taint nodes node1 key1=value1:NoSchedule
Taint effect can be of two types.
a. NoSchedule – This will not allow any new Pod scheduling with the tainted node, if the Pod doesn’t have the required toleration. However, the existing pods will continue to run in the node.
b. NoExecute – This will not only disallow any new Pod scheduling with the tainted node, if the Pod doesn’t have the required toleration, but also evict any existing Pod from the node.
Use the below command to remove a taint from node.
kubectl taint nodes node1 key1=value1:NoSchedule-
Now, in order to add tolerations to a Pod, so that it is allowed to be deployed in node1, use below yaml.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
app: tomcat-toleration
name: tomcat-toleration
spec:
containers:
- image: tomcat
name: tomcat-toleration
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
2. Using NodeAffinity
NodeAffinity can be used to control node scheduling in an even granular way, as compared to taints and tolerations. For example, you can label few of the nodes with certain attributes (e.g. size=large), and then let Pods that need more capacity to be only scheduled in such nodes.
This is how you can show the current labels of a node.
kubectl get nodes --show-labels
Use below command to set new labels to a node.
kubectl label nodes kubenode01 size=large
Now, you need to use nodeSelector in a Pod to get it scheduled in nodes with a particular label.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
app: tomcat-affinity
name: tomcat-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- large
containers:
- image: tomcat
name: tomcat-affinity
Another way is to use the nodeSelector attibute.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
app: tomcat-affinity
name: tomcat-affinity
spec:
nodeSelector:
size: large
containers:
- image: tomcat
name: tomcat-affinity
Upgrade a Kubernetes Cluster
Upgrading a Kubernetes Cluster needs a proper understanding of the procedure and few of the preset conditions to avoid unforeseen issues. Let’s look at few of the important facts about the Cluster version.
1. A cluster built using kubeadm will have the same version as the kubeadm tool.
2. Check the version of the cluster either by using the kubeadm version or the version returned while listing the nodes.
root@kubemaster:~# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.2", GitCommit:"5835544ca568b757a8ecae5c153f317e5736700e", GitTreeState:"clean", BuildDate:"2022-09-21T14:32:18Z", GoVersion:"go1.19.1", Compiler:"gc", Platform:"linux/amd64"}
root@kubemaster:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubemaster Ready control-plane 15d v1.25.2
kubenode01 Ready <none> 15d v1.25.2
kubenode02 Ready <none> 15d v1.25.2
root@kubemaster:~#
As you can see, the version of the Kubernetes cluster here is 1.25.2
3. Kubernetes Cluster version consists of a major version (1), a minor version (25) and a patch version (2)
4. Cluster upgrade has to be done from one minor version to the next. For example, if you need to upgrade a cluster from 1.22 to 1.24, first upgrade to 1.23 and then to 1.24.
Now, let’s look at the overall Cluster upgrade steps.
1. Login to the Controlplane node and check the current cluster version
2. Upgrade the kubeadm to the target version
3. Check the available versions to upgrade the node
kubeadm upgrade plan
4. Drain the control plane node and cordon
kubectl drain kubemaster --ignore-daemonsets kubectl cordon kubemaster
5. Upgrade the control plan node
kubeadm upgrade apply <target version>
6. Upgrade the kubelet in the control plane and restart the kubelet daemon
7. Now, you should see the new version of the control plane node while calling kubectl get nodes
8. Uncordon the control plane node
9. Login to the worker node
10. Drain and cordon the worker node
11. Upgrade the kubelet and restart the daemon
Now, you should see the new version in both the nodes while executing kubectl get nodes
Refer to the upgrade documentation here.
Pods with multiple containers
1. To view the logs of a particular container of a multi pod container, use below command.
kubectl logs tomcat-cm -c openjdk -f
Here, tomcat-cm is the Pod name and openjdk is the name of the container inside the Pod, whose logs you want to view.
Execute multiple commands, grouped together, in a Pod
Look at how to insert multiple commands to execute in a Pod.
apiVersion: v1
kind: Pod
metadata:
name: openjdk
spec:
containers:
- name: openjdk
image: openjdk
command: ["/bin/bash"]
args: ["-c", "while true; do curl http://targethost:8080/; sleep 5; done"]
Generating K8S object’s definition files using imperative commands
You can use imperative commands to generate the yaml files without creating the objects.
kubectl run tomcat --image=tomcat --dry-run=client -o yaml
Above command generates the below Pod definition file.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: tomcat
name: tomcat
spec:
containers:
- image: tomcat
name: tomcat
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Mount a Volume into Pods
When a file or directory needs to be persisted beyond the lifecycle of the Pod, you need to use Volumes. In addition, it can be used to share files across Pods as well, since the same host path can be mounted as Volumes in multiple Pods.
Look at the Pod definition below to see how Volumes and VolumeMounts are defined.
apiVersion: v1
kind: Pod
metadata:
labels:
app: openjdk
name: openjdk
spec:
containers:
- image: openjdk
name: openjdk
command: ["touch", "/test-pd/test.txt"]
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /tmp/hello
# this field is optional
type: DirectoryOrCreate
Note that the path /tmp/hello is on the Kubernetes host (any of the cluster hosts, where the Pod gets scheduled) and not on the client host from where you execute the kubectl apply command.
The hostPath volume is not really preferred and is better to avoid in production clusters. Another volume type is emptyDir, which persists the lifetime of a Pod. It a Pod is deleted, the emptyDir volume is destroyed as well.
K8S Cluster Components and Configurations
Look at the overall architecture of the different components.
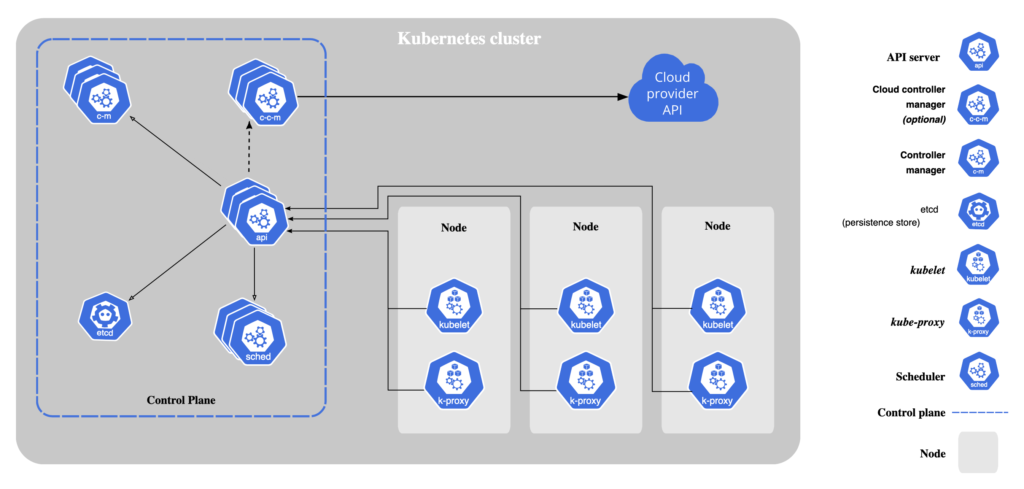
Let’s understand the below 6 most important components and their related configuration locations.
1. Kubernetes API Server – This is the heart of the K8S cluster. The Kubernetes API Server is the master that governs the whole cluster. It exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane.
Kube API Server Configuration File
The Kube API Server is deployed as a static Pod, when the cluster is built using Kubeadm utility. Look at the configuration file under the below path.
/etc/kubernetes/manifests/kube-apiserver.yaml
Important Configurations
- --advertise-address=192.168.56.2 # This is the control plane node IP
- --allow-privileged=true
- --authorization-mode=Node,RBAC # The API Server tries to authorise user with the help of Node auth. If it fails, it tries with RBAC. If anyone of the methods is successful, then the API server stops the authorisation flow and returns success
- --client-ca-file=/etc/kubernetes/pki/ca.crt # Clients are validated based on this CA
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
# Below cert configurations are to connect to the ETCD
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
# Below are kubelet certs configurations
- --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt
- --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
- --requestheader-allowed-names=front-proxy-client
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User
# API Server Port
- --secure-port=6443
- --service-account-issuer=https://kubernetes.default.svc.cluster.local
- --service-account-key-file=/etc/kubernetes/pki/sa.pub
- --service-account-signing-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
# Below are the server certs for the API Server
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
2. ETCD – This is the Kubernetes database that stores all configurations of the Cluster. The Kubernetes API Server connects to the ETCD store to lookup the cluster configurations.
3. Schedular – The Schedular is responsible to schedule Pods in a particular node of the cluster. It connects with the API Server to schedule the Pods. The decision to choose the node to schedule is based on various factors e.g. load distribution on the cluster nodes, taints in the nodes and the respective tolerations in the Pods, node and Pod labels, Pod configuration on nodeAffinity and anti-affinity etc.
4. Controller Manager – The controller manager is responsible for managing the overall certificate management in the Cluster.
4. Kubelet – Every node including the control plane and the worker nodes runs an instance of the kubelet. It help to execute the low level tasks of running the commands as directed by the Kubernetes API Server. Note that the Kubelet is deployed in each node as a system service. It can be restarted using the below commands.
systemctl stop kubelet systemctl start kubelet
The kubelet writes its output into the system logs in the below path.
/var/log/syslog
Below are the important configuration files related to kubelet.
/var/lib/kubelet/config.yaml /etc/kubernetes/kubelet.conf
5. Kube-proxy – The Kube API Server connects to the worker Kubelets via the Kube-proxy nodes, running in each of the worker nodes. The Kube proxy uses one of the many networking solutions as mentioned here.
Troubleshooting Kubernetes Cluster issues
Troubleshooting cluster issues may be sometimes tricky. There can be failure in a particular Pod, or the core Cluster Pods in the kube-system namespace. Follow the below options to look at various components to drill down.
1. Any Pod deployment is taken care by the kubelet in a node. You can look at the kubelet logs at below location. This is very helpful in case the Pod doesn’t come up at all and is in the CrashLoopBackOff state.
/var/log/syslog
2. You can always describe any object to look at its definition as well as the events.
root@kubenode01:/var/log# kubectl describe pod openjdk-static -n=kube-system
Name: openjdk-static
Namespace: kube-system
Priority: 0
Service Account: default
Node: kubenode01/192.168.56.3
Start Time: Sun, 09 Oct 2022 15:12:56 +0000
Labels: app=openjdki-_static
Annotations: <none>
Status: Running
IP: 10.44.0.4
IPs:
IP: 10.44.0.4
Containers:
openjdk-static:
Container ID: containerd://5110c53f7002f75f56e2a260ada15fa2a63b2cb35a655dc00c09ac58c1c45f57
Image: openjdk
Image ID: docker.io/library/openjdk@sha256:5f9ad1da305e5553bdf87587c0cefc7ea1155717561f7a59c7c7cf6afd964860
Port: <none>
Host Port: <none>
Command:
/bin/sh
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Sun, 09 Oct 2022 15:29:05 +0000
Finished: Sun, 09 Oct 2022 15:29:05 +0000
Ready: False
Restart Count: 8
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-7hwb4 (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-7hwb4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 19m default-scheduler Successfully assigned kube-system/openjdk-static to kubenode01
Normal Pulled 19m kubelet Successfully pulled image "openjdk" in 2.644851296s
Normal Pulled 19m kubelet Successfully pulled image "openjdk" in 2.865001933s
Normal Pulled 18m kubelet Successfully pulled image "openjdk" in 2.493483455s
Normal Created 18m (x4 over 19m) kubelet Created container openjdk-static
Normal Started 18m (x4 over 19m) kubelet Started container openjdk-static
Normal Pulled 18m kubelet Successfully pulled image "openjdk" in 2.696294524s
Normal Pulling 17m (x5 over 19m) kubelet Pulling image "openjdk"
Warning BackOff 4m10s (x70 over 19m) kubelet Back-off restarting failed container
root@kubenode01:/var/log#
3. Look at all the events in a cluster
root@kubenode01:/var/log# kubectl get events -A NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE default 79m Normal NodeSchedulable node/kubemaster Node kubemaster status is now: NodeSchedulable default 5s Normal CIDRNotAvailable node/kubenode01 Node kubenode01 status is now: CIDRNotAvailable default 3m4s Normal CIDRNotAvailable node/kubenode02 Node kubenode02 status is now: CIDRNotAvailable default 2m17s Warning BackOff pod/openjdk Back-off restarting failed container default 10m Normal Scheduled pod/tomcat-simple Successfully assigned default/tomcat-simple to kubenode01 default 10m Normal Pulling pod/tomcat-simple Pulling image "tomcat" default 10m Normal Pulled pod/tomcat-simple Successfully pulled image "tomcat" in 5.889094912s default 10m Normal Created pod/tomcat-simple Created container tomcat-simple default 10m Normal Started pod/tomcat-simple Started container tomcat-simple kube-system 36m Normal Pulling pod/openjdk-static-kubemaster Pulling image "openjdk" kube-system 38m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 51.801194905s kube-system 37m Normal Created pod/openjdk-static-kubemaster Created container openjdk-static kube-system 37m Normal Started pod/openjdk-static-kubemaster Started container openjdk-static kube-system 38m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.887246274s kube-system 28m Warning BackOff pod/openjdk-static-kubemaster Back-off restarting failed container kube-system 37m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.605051839s kube-system 37m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.819365398s kube-system 36m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.644104546s kube-system 25m Normal Pulling pod/openjdk-static-kubemaster Pulling image "openjdk" kube-system 27m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.726934758s kube-system 26m Normal Created pod/openjdk-static-kubemaster Created container openjdk-static kube-system 26m Normal Started pod/openjdk-static-kubemaster Started container openjdk-static kube-system 27m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.716457399s kube-system 22m Warning BackOff pod/openjdk-static-kubemaster Back-off restarting failed container kube-system 27m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.883168752s kube-system 26m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.366318707s kube-system 19m Normal Pulling pod/openjdk-static-kubemaster Pulling image "openjdk" kube-system 19m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.5408814s kube-system 19m Normal Created pod/openjdk-static-kubemaster Created container openjdk-static kube-system 19m Normal Started pod/openjdk-static-kubemaster Started container openjdk-static kube-system 19m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.89498859s kube-system 19m Warning BackOff pod/openjdk-static-kubemaster Back-off restarting failed container kube-system 19m Normal Pulled pod/openjdk-static-kubemaster Successfully pulled image "openjdk" in 2.779902318s kube-system 22m Normal Scheduled pod/openjdk-static Successfully assigned kube-system/openjdk-static to kubenode01 kube-system 20m Normal Pulling pod/openjdk-static Pulling image "openjdk" kube-system 21m Normal Pulled pod/openjdk-static Successfully pulled image "openjdk" in 2.644851296s kube-system 21m Normal Created pod/openjdk-static Created container openjdk-static kube-system 21m Normal Started pod/openjdk-static Started container openjdk-static kube-system 21m Normal Pulled pod/openjdk-static Successfully pulled image "openjdk" in 2.865001933s kube-system 119s Warning BackOff pod/openjdk-static Back-off restarting failed container kube-system 21m Normal Pulled pod/openjdk-static Successfully pulled image "openjdk" in 2.493483455s kube-system 21m Normal Pulled pod/openjdk-static Successfully pulled image "openjdk" in 2.696294524s kube-system 19m Normal Pulling pod/tomcat-static-kubemaster Pulling image "tomcat" kube-system 18m Normal Pulled pod/tomcat-static-kubemaster Successfully pulled image "tomcat" in 51.318187575s kube-system 18m Normal Created pod/tomcat-static-kubemaster Created container tomcat-static kube-system 18m Normal Started pod/tomcat-static-kubemaster Started container tomcat-static root@kubenode01:/var/log#
4. In case of any issue with the nodes, check the kubelet logs.
journalctl -u kubelet
Static Pods
These are Pods that are auto scheduled in a node directly by the kubelet. You can use this technique to deploy a Pod even when the Kube API Server is not up. In fact, the Kube API server itself is deployed as a static Pod, when the control plane node boots up. You can create a static Pod by placing the Pod definition file under below location.
/etc/kubernetes/manifests/
Configure Ingress/Egress Network Policies
If you want to control traffic flow at the IP address or port level (OSI layer 3 or 4), then you might consider using Kubernetes NetworkPolicies for particular applications in your cluster. NetworkPolicies are an application-centric construct which allow you to specify how a pod is allowed to communicate with various network “entities” over the network.
Network policies do not conflict; they are additive. If any policy or policies select a pod, the pod is restricted to what is allowed by the union of those policies’ ingress/egress rules. Thus, order of evaluation does not affect the policy result.
For a network flow between two pods to be allowed, both the egress policy on the source pod and the ingress policy on the destination pod need to allow the traffic. If either the egress policy on the source, or the ingress policy on the destination denies the traffic, the traffic will be denied.
Details on Network Policy Configuration can be found here
Let’s understand few salient points about Network Policies.
1. By default, traffic between Pods and Services remain unrestricted.
2. To associate a Network Policy with a Pod, use the podSelector and create the Network Policy in the same namespace as that of the Pod. The below policy will associate itself with the Pod that has role=db as one of the labels in the default namespace.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
3. Specify the policyTypes in the Network Policy as Ingress or Egress. If both are mentioned, then all traffic in and out of a Pod are restricted. If only Ingress is specified, then all incoming traffic is restricted, but all outgoing traffic are allowed. Similarly if only Egress is specified, then all outgoing traffic is restricted, but all incoming traffic is allowed.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
4. For both policy types, you can mention the rules as below.
- Ingress
- from
- ipBlock
- namespaceSelector
- podSelector
- ports
- from
- Egress
- to
- ipBlock
- namespaceSelector
- podSelector
- ports
- to
Note that the Network Policy combines the from or the to clauses (e.g. ipBlock, namespaceSelector, podSelector) with OR operator to make a final access decision. However, multiple clauses in one condition are combined with AND operator. Let’s consider below policy to understand this better.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
The above policy indicates that all outbound traffic from the Pod labelled role=db in the default namespace are restricted. It also indicates that traffic from 172.17.0.0/16 network or all Pods in the namespace labelled project=myproject or from the Pods labelled role=frontend in the default namespace are allowed to connect to the Pod labelled role=db on Port 6379 in the default namespace.
Now look at the below policy.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
See how the ipBlock and the namespaceSelector have been combined in one rule in this case. Everything remains same as the earlier definition, but in this case, for the inbound traffic, all Pods in the namespace labelled project=myproject and in the cidr range 172.17.0.0/16 or from the Pods labelled role=frontend in the default namespace are allowed to connect to the Pod labelled role=db on Port 6379 in the default namespace.
DNS access for pods and services
A Service can be accessed from any Pod in the Cluster using <service-name>.<namespace>
Example: If the service name is frontend-service and is in the default namespace, you can access it just by using the same name
kubectl run test –image=busybox:1.28 –rm –restart=Never -it — nslookup frontend-service
Append the namespace, if it is not default. For example, to access frontend-service in hr-app namespace, use below.
kubectl run test –image=busybox:1.28 –rm –restart=Never -it — nslookup frontend-service.hr-app
A Pod can be accessed from another Pod using the IP of the Node on which it is scheduled, but in a typical format.
If the IP where the Pod is deployed is 10.42.0.9, you can access it using 10-42-0-9.default.pod, where default is the namespace
kubectl run test –image=busybox:1.28 –rm –restart=Never -it — nslookup 10-42-0-9.default.pod
Link PersistentVolume PersistentVolumeClaim and Pod
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. It is a resource in the cluster just like a node is a cluster resource. PVs are volume plugins like Volumes, but have a lifecycle independent of any individual Pod that uses the PV. This API object captures the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system.
A PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes (e.g., they can be mounted ReadWriteOnce, ReadOnlyMany or ReadWriteMany, see AccessModes).
Further details can be found here
Let’s look at how to create a PersistentVolume of type hostPath, and a PersistentVolumeClaim to bind to it, and finally a Pod to use the PersistentVolumeClaim.
1. Create a PersistentVolume of type hostPath
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
2. Create a PersistentVolumeClaim to bind to the PersistentVolume
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
3. Create a Pod to use the PersistentVolumeClaim
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
Refer to the official documentation for more details.
Jsonpath queries
1. Print all the node names in the cluster
kubectl get nodes -o=jsonpath='{.items[*].metadata.name}'
2. Print the IP Addresses of all nodes in the cluster, in a column format
kubectl get nodes -o custom-columns=IP:.status.addresses[0].address
IP
10.30.164.6
10.30.164.8
3. Print all the “kubectl get nodes” output, sorted by the node name.
kubectl get nodes --sort-by=.metadata.name
4. You can combine both custom-columns along with sort-by. Look at the below query as an example.
kubectl get pv --sort-by=.spec.capacity.storage -o=custom-columns=NAME:.metadata.name,CAPACITY:.spec.capacity.storage
5. You can also use a condition to filter the queries. Look at the below example.
kubectl config view --kubeconfig=/root/my-kube-config -o jsonpath="{.contexts[?(@.context.user=='aws-user')].name}"
Here, we are displaying the kubeconfig file at /root/my-kube-config and filter the context for the user ‘aws-user’.
? denotes a condition and @ denotes each elements of the array.
Take etcd backup and restore
ETCDCTL_API=3 etcdctl –cacert=<cacert_file_path> –cert=<cert_file_path> –key=<key_path> –endpoints=<etcd_server_url> snapshot save /tmp/snapshot-pre-boot.db
ETCDCTL_API=3 etcdctl –cacert=<cacert_file_path> –cert=<cert_file_path> –key=<key_path> –endpoints=<etcd_server_url> snapshot status /tmp/snapshot-pre-boot.db
ETCDCTL_API=3 etcdctl –cacert=<cacert_file_path> –cert=<cert_file_path> –key=<key_path> –data-dir=<data_directory_path> –endpoints=<etcd_server_url> snapshot restore /tmp/snapshot-pre-boot.db
Once data is restored in the control plane node, you need to update the hostPath in etcd.yaml with the new path and restart the service. For clusters that are built using Kubeadm tool, the etcd.yaml is placed inside manifest and it is automatically redeployed with the new configuration
Note that you need to update the new path in two places in the etcd.yaml as highlighted below.
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.56.2:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.56.2:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.168.56.2:2380
- --initial-cluster=kubemaster=https://192.168.56.2:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.56.2:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.56.2:2380
- --name=kubemaster
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.k8s.io/etcd:3.5.4-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health?exclude=NOSPACE&serializable=true
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: etcd
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /health?serializable=false
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /etc/kubernetes/pki/default.etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
Note: All the etcd certificates can be found under /etc/kubernetes/pki
Note: data-dir can be found in /etc/kubernetes/manifest/etcd.yaml
While performing the restore, you may encounter below error.
root@kubemaster:/tmp/etcd# ETCDCTL_API=3 etcdctl snapshot restore /tmp/etcd/newsnap3 --data-dir=/tmp/etcd/newsnaprestore3 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cert="/etc/kubernetes/pki/etcd/server.crt" Error: expected sha256 [151 216 219 18 28 224 183 90 24 6 149 9 212 178 63 233 71 198 112 18 84 186 32 198 239 245 30 26 218 238 14 64], got [123 55 39 232 116 48 29 132 20 107 167 99 211 199 52 250 150 123 78 143 23 83 37 154 14 201 105 112 29 63 226 25]
To workaround this, use an additional flag –skip-hash-check=true to skip the hash check.
root@kubemaster:/etc/kubernetes/pki# ETCDCTL_API=3 etcdctl snapshot restore /tmp/etcd/newsnap3 --data-dir=/tmp/etcd/newsnaprestore3 --cacert=ca.crt --key=apiserver-etcd-client.key --cert=apiserver-etcd-client.crt --skip-hash-check=true 2022-10-22 04:15:10.611849 I | mvcc: restore compact to 235247 2022-10-22 04:15:10.627067 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
Link service account to Pod
Follow the instructions here
Taints and Tolerations
Add taint:
kubectl taint nodes node1 key1=value1:NoScheduleRemove taint:
kubectl taint nodes node1 key1=value1:NoSchedule-Follow this link for further configuration
Create user using csr, approve and configure context and validate
Follow the steps from here
Bootstrapping a Kubernetes Cluster using Kubeadm
Bootstrapping a kubernetes cluster can really become a daunting task. The different issues can be difficult to deal with. Moreover, the documentation is very extensive and following each line of text may not be possible. So, let’s understand the overall steps, so that you can filter the documentation and choose the right set of actions.
1. Make sure that you have at least 2 Virtual Machines – one for the master and the other for worker node
2. Each of the nodes should possess a minimum of 2 CPU and 2 GB of memory (RAM)
3. Install a container runtime engine e.g. Docker in each of the nodes
4. Install Kubeadm, kubelet, kubectl
5. Delete /etc/containerd/config.toml
6. Restart the container runtime engine. This is a must without which the kubeadm commands will not work.
7. Initialize the master node. Note that the –pod-network-cidr and the –apiserver-advertise-address parameters are very important to specify
kubeadm init --pod-network-cidr=<cidr of the provisioned nodes> --apiserver-advertise-address=<master node ip>
8. Get the join command from the master node
kubeadm token create --print-join-command
9. Run the output of the join command in the worker node after preparing the worker node. Make sure you go through all the steps from Step 1 – 6 before running the join command.
10. After setting up the cluster, you need to create the below file, without which kubectl commands won’t work.
<USER_HOME>/.kube/config
Copy the contents of /etc/kubernetes/admin.conf into the above file. Note that this should be done only in the master node.
Important paths and files to remember in a Kubernetes Cluster
1. Below file needs to be copied from the master node to run any kubectl commands on any node.
/etc/kubernetes/admin.conf
2. All configuration related to the Kubernetes core services e.g. kubelet, scheduler, controllers etc. are present in the below path.
/etc/kubernetes
3. Difference in the file list between master and worker nodes under /etc/kubernetes/
Master Node drwxr-xr-x 3 root root 4096 Sep 22 02:11 pki -rw------- 1 root root 5640 Sep 22 02:11 admin.conf -rw------- 1 root root 5672 Sep 22 02:11 controller-manager.conf -rw------- 1 root root 5620 Sep 22 02:11 scheduler.conf drwxr-xr-x 2 root root 4096 Sep 22 02:11 manifests -rw------- 1 root root 1976 Sep 22 02:11 kubelet.conf Worker Node drwxr-xr-x 2 root root 4096 Sep 22 02:16 manifests drwxr-xr-x 2 root root 4096 Sep 22 02:29 pki -rw------- 1 root root 1953 Sep 22 02:29 kubelet.conf
4. Difference in the list of certs available between the master and worker nodes under /etc/kubernetes
Master Node -rw------- 1 root root 1679 Sep 22 02:11 ca.key -rw-r--r-- 1 root root 1099 Sep 22 02:11 ca.crt -rw------- 1 root root 1679 Sep 22 02:11 apiserver.key -rw-r--r-- 1 root root 1285 Sep 22 02:11 apiserver.crt -rw------- 1 root root 1675 Sep 22 02:11 apiserver-kubelet-client.key -rw-r--r-- 1 root root 1164 Sep 22 02:11 apiserver-kubelet-client.crt -rw------- 1 root root 1679 Sep 22 02:11 front-proxy-ca.key -rw-r--r-- 1 root root 1115 Sep 22 02:11 front-proxy-ca.crt -rw------- 1 root root 1679 Sep 22 02:11 front-proxy-client.key -rw-r--r-- 1 root root 1119 Sep 22 02:11 front-proxy-client.crt drwxr-xr-x 2 root root 4096 Sep 22 02:11 etcd -rw------- 1 root root 1675 Sep 22 02:11 apiserver-etcd-client.key -rw-r--r-- 1 root root 1155 Sep 22 02:11 apiserver-etcd-client.crt -rw------- 1 root root 451 Sep 22 02:11 sa.pub -rw------- 1 root root 1679 Sep 22 02:11 sa.key Worker Node -rw-r--r-- 1 root root 1099 Sep 22 02:29 ca.crt
5. Logs to look at for failures
System Logs -> /var/log/syslog Journal Logs -> journalctl
6. Those services that need to be started as daemonsets retrieve their configurations from below path
/etc/kubernetes/manifests
More on JSONPATH
You can display the configuration of any object in kubernetes in the form of a json using below command.
kubectl get pod <podname> -o json
Normally, we always work with yaml in kubernetes, but in few cases, the yaml is quite large and there are too many nested items. You may be interested in just a few fields out of the complete yaml or json. In such scenarios JSONPATH comes as a rescue. It helps to provide the nested path of the element, you are interested in, to extract its value. Below is an example.
kubectl get pods -o jsonpath='{.items[0].status.hostIP}'
Normally, all JSONPATH will start with $, which represents the root element of the json, followed by the other nested elements. All kubernetes objects, in json format, will have items, as the first element. There can be multiple items, and we can specify all such elements in the JSONPATH using items[*], or only one element using items[<index>], as shown in the above example.
Let’s look at the json output and try to get the node names using jsonpath.\
kubectl get nodes -o jsonpath='{.items[*].metadata.name}'
Output -> kubemaster kubenode01 kubenode02
Suppose you want to print these nodes a a nice table, then use below command.
kubectl get nodes -o=custom-columns='NODENAME:.metadata.name' Output -> NODENAME kubemaster kubenode01 kubenode02
Note that for custom-columns, the .items[*] is considered by default, and you don’t have to mention that. Just start the JSONPATH after items[*], otherwise it returns an error.
This is how you specify multiple columns.
kubectl get nodes -o=custom-columns='NODE:.metadata.name, CREATIONTIME:.metadata.creationTimestamp' Output -> NODE CREATIONTIME kubemaster 2022-09-22T02:11:28Z kubenode01 2022-09-22T02:30:12Z kubenode02 2022-09-22T03:13:12Z
Networking in Kubernetes
1. Networking Essentials – CNI Network and DNS
Networking in Kubernetes is based on the namespace features of the Linux Kernel. Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources. The feature works by having the same namespace for a set of resources and processes, but those namespaces refer to distinct resources. Resources may exist in multiple spaces. Examples of such resources are process IDs, hostnames, user IDs, file names, and some names associated with network access, and interprocess communication.
Kubernetes encapsulates applications as Pods, and Pods are exposed for access using Services. Pods are deployed to Nodes, but Services are not Node specific, rather Cluster Specific. After a Pod is created by the Kubelet in a node, all the networking related to the Pod has to be created as well. However, instead of doing all the hard work, the Kubelet outsource the networking part with the help of one of the several CNI networking solutions available in the market. Below are a few well known networking solutions for Kubernetes.
- ACI provides integrated container networking and network security with Cisco ACI.
- Antrea operates at Layer 3/4 to provide networking and security services for Kubernetes, leveraging Open vSwitch as the networking data plane.
- Calico is a networking and network policy provider. Calico supports a flexible set of networking options so you can choose the most efficient option for your situation, including non-overlay and overlay networks, with or without BGP. Calico uses the same engine to enforce network policy for hosts, pods, and (if using Istio & Envoy) applications at the service mesh layer.
- Canal unites Flannel and Calico, providing networking and network policy.
- Cilium is a networking, observability, and security solution with an eBPF-based data plane. Cilium provides a simple flat Layer 3 network with the ability to span multiple clusters in either a native routing or overlay/encapsulation mode, and can enforce network policies on L3-L7 using an identity-based security model that is decoupled from network addressing. Cilium can act as a replacement for kube-proxy; it also offers additional, opt-in observability and security features.
- CNI-Genie enables Kubernetes to seamlessly connect to a choice of CNI plugins, such as Calico, Canal, Flannel, or Weave.
- Contiv provides configurable networking (native L3 using BGP, overlay using vxlan, classic L2, and Cisco-SDN/ACI) for various use cases and a rich policy framework. Contiv project is fully open sourced. The installer provides both kubeadm and non-kubeadm based installation options.
- Contrail, based on Tungsten Fabric, is an open source, multi-cloud network virtualization and policy management platform. Contrail and Tungsten Fabric are integrated with orchestration systems such as Kubernetes, OpenShift, OpenStack and Mesos, and provide isolation modes for virtual machines, containers/pods and bare metal workloads.
- Flannel is an overlay network provider that can be used with Kubernetes.
- Knitter is a plugin to support multiple network interfaces in a Kubernetes pod.
- Multus is a Multi plugin for multiple network support in Kubernetes to support all CNI plugins (e.g. Calico, Cilium, Contiv, Flannel), in addition to SRIOV, DPDK, OVS-DPDK and VPP based workloads in Kubernetes.
- OVN-Kubernetes is a networking provider for Kubernetes based on OVN (Open Virtual Network), a virtual networking implementation that came out of the Open vSwitch (OVS) project. OVN-Kubernetes provides an overlay based networking implementation for Kubernetes, including an OVS based implementation of load balancing and network policy.
- Nodus is an OVN based CNI controller plugin to provide cloud native based Service function chaining(SFC).
- NSX-T Container Plug-in (NCP) provides integration between VMware NSX-T and container orchestrators such as Kubernetes, as well as integration between NSX-T and container-based CaaS/PaaS platforms such as Pivotal Container Service (PKS) and OpenShift.
- Nuage is an SDN platform that provides policy-based networking between Kubernetes Pods and non-Kubernetes environments with visibility and security monitoring.
- Romana is a Layer 3 networking solution for pod networks that also supports the NetworkPolicyAPI.
- Weave Net provides networking and network policy, will carry on working on both sides of a network partition, and does not require an external database.
Apart from the networking solutions, you also need to choose a DNS solution. By default, the kubeadm tool uses CoreDNS while deploying a brand new cluster.
Once a cluster is built using Kubeadm, you should see both the networking solution as well as the DNS solution deployed as Pods in the Kube-system namespace.
bash-3.2$ k get pods -n kube-system|egrep "dns|net" coredns-565d847f94-f85b2 1/1 Running 0 13d coredns-565d847f94-zhm2n 1/1 Running 0 10d weave-net-knqpj 2/2 Running 0 26d weave-net-nv6k5 2/2 Running 1 (26d ago) 26d weave-net-w6956 2/2 Running 1 (26d ago) 26d
In our example cluster, we see CoreDNS and Weave already deployed. In case you are building a Cluster from scratch, you may have to install and run these services separately. Without them, the Cluster will not function.
The configuration for the CNI network can be found in below path.
/etc/cni/net.d/
For DNS configuration, look at the Kubelet configuration in below path.
root@kubemaster:/etc# cat /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
resolvConf: /run/systemd/resolve/resolv.conf
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
Once you exec to any of the Pods, you will see the DNS configuration pointing to the same name server inside the Pod.
cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5
2. Accessing Pods and Services
When an application deployed in a Pod needs to be accessed by a client, it should be exposed in the form of a service.
kubectl expose pod <pod_name> --name=<service_name> --port=<service_port> --target-port=<container_port> --type=NodePort
Once the pod is exposed, you can access the service either from within the Cluster (in case of ClusterIP service) or from outside (using NodePort).
3. How the IP ranges are allocated to nodes, pods and services
To understand the networking configurations in a Cluster, you should inspect all the below aspects.
a. Which networking solution is being used?
You can either inspect the pods in the kube-system namespace or check the configurations under /etc/cni/net.d
root@kubemaster:/etc/cni/net.d# cd /etc/cni/net.d/
root@kubemaster:/etc/cni/net.d# ls -lrt
total 4
-rw-r--r-- 1 root root 318 Sep 22 02:40 10-weave.conflist
root@kubemaster:/etc/cni/net.d# cat 10-weave.conflist
{
"cniVersion": "0.3.0",
"name": "weave",
"plugins": [
{
"name": "weave",
"type": "weave-net",
"hairpinMode": true
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"snat": true
}
]
}
root@kubemaster:/etc/cni/net.d# kubectl get pods -n kube-system|grep net
weave-net-knqpj 2/2 Running 0 31d
weave-net-nv6k5 2/2 Running 0 31d
weave-net-w6956 2/2 Running 0 31d
b. Where are the network binaries and configurations?
Binary Location
root@kubemaster:~# cd /opt/cni/bin/
root@kubemaster:/opt/cni/bin# ls -lrt
total 81668
-rwxr-xr-x 1 root root 4159518 May 13 2020 bandwidth
-rwxr-xr-x 1 root root 5945760 May 13 2020 firewall
-rwxr-xr-x 1 root root 3069556 May 13 2020 flannel
-rwxr-xr-x 1 root root 3392826 May 13 2020 sbr
-rwxr-xr-x 1 root root 3939867 May 13 2020 portmap
-rwxr-xr-x 1 root root 3356587 May 13 2020 tuning
-rwxr-xr-x 1 root root 4671647 May 13 2020 bridge
-rwxr-xr-x 1 root root 4174394 May 13 2020 host-device
-rwxr-xr-x 1 root root 4314598 May 13 2020 ipvlan
-rwxr-xr-x 1 root root 3209463 May 13 2020 loopback
-rwxr-xr-x 1 root root 4389622 May 13 2020 macvlan
-rwxr-xr-x 1 root root 4590277 May 13 2020 ptp
-rwxr-xr-x 1 root root 4314446 May 13 2020 vlan
-rwxr-xr-x 1 root root 12124326 May 13 2020 dhcp
-rwxr-xr-x 1 root root 2885430 May 13 2020 static
-rwxr-xr-x 1 root root 3614480 May 13 2020 host-local
-rwxr-xr-x 1 root root 11437320 Sep 22 02:40 weave-plugin-2.8.1
lrwxrwxrwx 1 root root 18 Sep 22 02:40 weave-net -> weave-plugin-2.8.1
lrwxrwxrwx 1 root root 18 Sep 22 02:40 weave-ipam -> weave-plugin-2.8.1
Configuration Location
root@kubemaster:/opt/cni# cd /etc/cni/net.d/
root@kubemaster:/etc/cni/net.d# ls -lrt
total 4
-rw-r–r– 1 root root 318 Sep 22 02:40 10-weave.conflist
c. What is the interface created by the networking solution?
You need to check the pod logs to find the interface used by the networking solution.
root@kubemaster:/var/lib/cni/results# k logs pod weave-net-knqpj -n kube-system
Error from server (NotFound): pods "pod" not found
root@kubemaster:/var/lib/cni/results# k logs weave-net-knqpj -n kube-system
Defaulted container "weave" out of: weave, weave-npc, weave-init (init)
DEBU: 2022/10/20 06:44:41.533061 [kube-peers] Checking peer "ae:3f:68:20:54:ee" against list &{[{6e:ba:5e:55:88:ca kubemaster} {ca:49:34:a5:76:60 kubenode01} {ae:3f:68:20:54:ee kubenode02}]}
INFO: 2022/10/20 06:44:41.629586 Command line options: map[conn-limit:200 datapath:datapath db-prefix:/weavedb/weave-net docker-api: expect-npc:true http-addr:127.0.0.1:6784 ipalloc-init:consensus=2 ipalloc-range:10.32.0.0/12 metrics-addr:0.0.0.0:6782 name:ae:3f:68:20:54:ee nickname:kubenode02 no-dns:true no-masq-local:true port:6783]
INFO: 2022/10/20 06:44:41.629613 weave 2.8.1
INFO: 2022/10/20 06:44:42.179921 Re-exposing 10.36.0.0/12 on bridge "weave"
INFO: 2022/10/20 06:44:42.257503 Bridge type is bridged_fastdp
INFO: 2022/10/20 06:44:42.257521 Communication between peers is unencrypted.
Now, look at the interface details using below command.
root@kubemaster:/var/lib/cni/results# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:de:0f:a2:7f:32 brd ff:ff:ff:ff:ff:ff
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:a4:30:10 brd ff:ff:ff:ff:ff:ff
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:5b:76:3e:b3 brd ff:ff:ff:ff:ff:ff
7: datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 12:38:a6:21:07:0a brd ff:ff:ff:ff:ff:ff
9: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 6e:ba:5e:55:88:ca brd ff:ff:ff:ff:ff:ff
11: vethwe-datapath@vethwe-bridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master datapath state UP mode DEFAULT group default
link/ether 92:b4:a5:35:7d:8a brd ff:ff:ff:ff:ff:ff
12: vethwe-bridge@vethwe-datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default
link/ether 32:23:49:7e:8f:15 brd ff:ff:ff:ff:ff:ff
23: vethweple245c48@if22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default
link/ether 8a:eb:03:99:9d:9b brd ff:ff:ff:ff:ff:ff link-netnsid 1
26: vxlan-6784: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65535 qdisc noqueue master datapath state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 5a:c6:fb:fd:64:8f brd ff:ff:ff:ff:ff:ff
Run the below command to check the IP Addresses assigned to the weave interface.
root@kubemaster:/var/lib/cni/results# ip a show weave
9: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether 6e:ba:5e:55:88:ca brd ff:ff:ff:ff:ff:ff
inet 10.32.0.1/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
inet6 fe80::6cba:5eff:fe55:88ca/64 scope link
valid_lft forever preferred_lft forever
d. What is the node ip range configured for the cluster?
The nodes use the eth0 interface which is the physical one. Calculate the ip range of the nodes using the ipcalc utility. Look at the below steps how the node’s ip range has been calculated.
root@kubemaster:~# k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kubemaster Ready control-plane 32d v1.25.2 192.168.56.2 <none> Ubuntu 18.04.6 LTS 4.15.0-192-generic containerd://1.6.8
kubenode01 Ready <none> 32d v1.25.2 192.168.56.3 <none> Ubuntu 18.04.6 LTS 4.15.0-192-generic containerd://1.6.8
kubenode02 Ready <none> 32d v1.25.2 192.168.56.4 <none> Ubuntu 18.04.6 LTS 4.15.0-192-generic containerd://1.6.8
root@kubemaster:~# ip a|grep 192.168
inet 192.168.56.2/24 brd 192.168.56.255 scope global enp0s8
root@kubemaster:~# ipcalc 192.168.56.2/24
Address: 192.168.56.2 11000000.10101000.00111000. 00000010
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
=>
Network: 192.168.56.0/24 11000000.10101000.00111000. 00000000
HostMin: 192.168.56.1 11000000.10101000.00111000. 00000001
HostMax: 192.168.56.254 11000000.10101000.00111000. 11111110
Broadcast: 192.168.56.255 11000000.10101000.00111000. 11111111
Hosts/Net: 254 Class C, Private Internet
We see that the nodes use the ip range 192.168.56.0/24
e. What is the Pod ip range of the cluster?
The Pod IPs are allocated by ethernet bridge created by the CNI networking solution (weave in our case). From the Pod logs of the CNI (weave), we can figure out which solution is being used and what should be the ip range of the pods.
DEBU: 2022/10/20 06:44:41.533061 [kube-peers] Checking peer "ae:3f:68:20:54:ee" against list &{[{6e:ba:5e:55:88:ca kubemaster} {ca:49:34:a5:76:60 kubenode01} {ae:3f:68:20:54:ee kubenode02}]}
INFO: 2022/10/20 06:44:41.629586 Command line options: map[conn-limit:200 datapath:datapath db-prefix:/weavedb/weave-net docker-api: expect-npc:true http-addr:127.0.0.1:6784 ipalloc-init:consensus=2 ipalloc-range:10.32.0.0/12 metrics-addr:0.0.0.0:6782 name:ae:3f:68:20:54:ee nickname:kubenode02 no-dns:true no-masq-local:true port:6783]
INFO: 2022/10/20 06:44:41.629613 weave 2.8.1
INFO: 2022/10/20 06:44:42.179921 Re-exposing 10.36.0.0/12 on bridge "weave"
Also, you can find the ip range looking at the weave interface.
root@kubemaster:~# ip a|grep weave
9: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
inet 10.32.0.1/12 brd 10.47.255.255 scope global weave
12: vethwe-bridge@vethwe-datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP group default
23: vethweple245c48@if22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP group default
root@kubemaster:~# ipcalc 10.32.0.1/12
Address: 10.32.0.1 00001010.0010 0000.00000000.00000001
Netmask: 255.240.0.0 = 12 11111111.1111 0000.00000000.00000000
Wildcard: 0.15.255.255 00000000.0000 1111.11111111.11111111
=>
Network: 10.32.0.0/12 00001010.0010 0000.00000000.00000000
HostMin: 10.32.0.1 00001010.0010 0000.00000000.00000001
HostMax: 10.47.255.254 00001010.0010 1111.11111111.11111110
Broadcast: 10.47.255.255 00001010.0010 1111.11111111.11111111
Hosts/Net: 1048574 Class A, Private Internet
f. What is the service ip range of the cluster?
The service ip range case be found from the definition of the kube-apiserver
root@kubemaster:~# k get pod kube-apiserver-kubemaster -n kube-system -o yaml|grep service
- --service-account-issuer=https://kubernetes.default.svc.cluster.local
- --service-account-key-file=/etc/kubernetes/pki/sa.pub
- --service-account-signing-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
root@kubemaster:~#
4. Ingress
To access a service from outside the Cluster, the recommended way in a Production cluster is to create an Ingress that proxies external requests and maps URLs with Kubernetes services and also provides load balancing features. An Ingress has two components.
- Ingress Controller
- Ingress Resource
See how the Ingress routes external requests to the internal services.
An Ingress may be configured to give Services externally-reachable URLs, load balance traffic, terminate SSL / TLS, and offer name-based virtual hosting. An Ingress controller is responsible for fulfilling the Ingress, usually with a load balancer, though it may also configure your edge router or additional frontends to help handle the traffic.
An Ingress does not expose arbitrary ports or protocols. Exposing services other than HTTP and HTTPS to the internet typically uses a service of type Service.Type=NodePort or Service.Type=LoadBalancer.
5. Configure Ingress Controller
In order for the Ingress resource to work, the cluster must have an ingress controller running.
Unlike other types of controllers which run as part of the kube-controller-manager binary, Ingress controllers are not started automatically with a cluster. Kubernetes as a project supports and maintains AWS, GCE, and nginx ingress controllers.
Follow the kubectl apply command specified here to get the Ingress Controller up and running in the cluster. Once it is configured, see the new objects that got configured as part of the controller.
bash-3.2$ k get all -A|grep ingress ingress-nginx pod/ingress-nginx-admission-create-5mzwv 0/1 Completed 0 4m5s ingress-nginx pod/ingress-nginx-admission-patch-lwtbp 0/1 Completed 0 4m5s ingress-nginx pod/ingress-nginx-controller-7844b9db77-5pdwg 1/1 Running 0 4m5s ingress-nginx service/ingress-nginx-controller LoadBalancer 10.98.129.198 <pending> 80:30159/TCP,443:31755/TCP 4m5s ingress-nginx service/ingress-nginx-controller-admission ClusterIP 10.97.63.206 <none> 443/TCP 4m5s ingress-nginx deployment.apps/ingress-nginx-controller 1/1 1 1 4m5s ingress-nginx replicaset.apps/ingress-nginx-controller-7844b9db77 1 1 1 4m5s ingress-nginx job.batch/ingress-nginx-admission-create 1/1 12s 4m5s ingress-nginx job.batch/ingress-nginx-admission-patch 1/1 15s 4m5s
Note that the ingress controller has a lot of dependencies and if it is not configured properly, it won’t work.
5. Configure the Ingress Resource
Once the controller is configured, you need to create the Ingress resources that defines the host and uri, where the requests are expected to arrive and also the service and port where the Ingress will redirect the traffic to. Let’s look at the Ingress definition file.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
The above resource defines two ingress rules.
http://foo.bar.com/bar ==> service1 and port 80
http://*.foo.com/foo ==>. service2 and port 80
Each HTTP rule contains the following information:
- An optional host. In this example, no host is specified, so the rule applies to all inbound HTTP traffic through the IP address specified. If a host is provided (for example, foo.bar.com), the rules apply to that host.
- A list of paths (for example,
/testpath), each of which has an associated backend defined with aservice.nameand aservice.port.nameorservice.port.number. Both the host and path must match the content of an incoming request before the load balancer directs traffic to the referenced Service. - A backend is a combination of Service and port names as described in the Service doc or a custom resource backend by way of a CRD. HTTP (and HTTPS) requests to the Ingress that matches the host and path of the rule are sent to the listed backend.
A defaultBackend is often configured in an Ingress controller to service any requests that do not match a path in the spec.
Imperative Commands Handbook
kubectl create serviceaccount pvviewer kubectl create clusterrole pvviewer-role --resource=persistentvolumes --verb=list kubectl create clusterrolebinding pvviewer-role-binding --clusterrole=pvviewer-role --serviceaccount=default:pvviewer
There are many other commands as referred to in the cheat sheet.
Important logs in troubleshooting failed clusters
For failed static pods in the kube-system namespace, look at the below log locations to find clues behind the failures.
/var/log/pods/* /var/log/containers/* /var/log/syslog