General Middleware
AWS Certified Solutions Architect – SAA-C02
Prelude
This tutorial is a summary of the different topics that appear in the AWS Certified Solutions Architect – SAA-C02 exam. Since, the number of services provided by AWS is huge, it is very confusing for the beginners to grab the overall picture in a short time. Go through this tutorial and feel free to refer to AWS Documentation for the detailed concepts.
Create your AWS Account
Register with AWS and get free usage to certain limited basic resources and services for 1 year. You need to enter your credit card, but there won’t be any changes deducted, unless you exceed Free Tier Usage Limits. There may be a 1$ transaction to your credit card for verification but that gets refunded.
Regions and Availability Zones

1. An Availability Zone (AZ) is one or more discrete data centers with redundant power, networking, and connectivity in an AWS Region. AZs give customers the ability to operate production applications and databases that are more highly available, fault tolerant, and scalable than would be possible from a single data center.
2. Find all the regions in the AWS Console at top right dropdown shown below.
Each of these regions have at least two availability zones, named with the Region code followed by a letter identifier; for example, us-east-2a
Global vs Regional Services
Most of the services in AWS are region specific, except a very few, which are global.
In the AWS Console, select a service to check whether it is global. Once selected, the region at the top right will change to global, if the service is so.

| Global Services/Names | Details |
| IAM | Identity Access Management |
| S3 bucket names | S3 bucket names are global, but the service itself is regional. When you create an S3 bucket, it is always created in a specific region. |
| Route 53 | This is the DNS service that AWS provides, and is global |
| AWS Global Accelerator | AWS Global Accelerator is a Global service that improves the availability and performance of your applications with local or global users. It provides static IP addresses that act as a fixed entry point to your application endpoints in a single or multiple AWS Regions, and uses the AWS global network to optimize the path from your users to your applications. |
| AWS CloudFront | Amazon CloudFront is a global service that provides fast content delivery network (CDN), which securely delivers data, videos, applications, and APIs to customers globally with low latency and high transfer speeds. |
| Regional Services | Details |
| Almost all AWS Services are regional. The list of such services are updated daily. | Here is the updated list. Note that this is just for reference, but you don’t need to memorize. |
Services which are AZ Specific
| Service | Details |
| EC2 | Need to choose the AZ while creating an EC2 instance |
| RDS | RDS is a regional service, by default, but you can make it specific to an AZ. |
Elastic Compute Cloud
Elastic Compute Cloud, commonly known as EC2, is the most popular service that provides compute engine (commonly called servers or VMs) to run your applications.
Types of EC2 Instances
1. There are many different EC2 instance types, however, just remember that broadly, there are 4 classes -> t, c, r, m
2. Each of these classes can have small to large capacity instances.
3. t and m are called general purpose since there is a balance between compute and memory for these instance classes
4. c class is for Compute Optimized
5. r class is for memory optimized
Example Instance Types : c6g.2xlarge, t3a.micro, m5d.large, r6gd.xlarge
Instance Provisioning
| Type | Description | Use Case |
| Spot Instance | This gives the least price, since you can bid for the instance price. When creating an EC2 instance, if you choose spot instance, then provide a bid price for the instance. However, if someone else bids more, your instances gets terminated. | Cost effective way to handle short workloads, that can stop and start anytime without impact. |
| Reserved Instance | Reserved Instance gives a lower price per hour, in case of reservation. You can reserve for either 1 year or 3 years. | Long workloads, anything from 1 – 3 years or more. AWS provides much lower price for Reserved Instance as compared to On-Demand. |
| On-Demand | Pay/Hour, higher Cost. | In case of unpredictable spikes in load, at unpredictable times, and when the workload cannot stop and start in between. |
| Dedicated Host | An Amazon EC2 Dedicated Host is a physical server fully dedicated for your use, so you can help address corporate compliance requirements. Dedicated Host is very expensive. | Amazon EC2 Dedicated Hosts allow you to use your eligible software licenses from vendors such as Microsoft and Oracle on Amazon EC2, so that you get the flexibility and cost effectiveness of using your own licenses, but with the resiliency, simplicity and elasticity of AWS. |
| Scheduled Instances | Provision on-demand EC2 instances at desired times only, and terminate them after the job is done. | Good for scheduled workloads, or to manage peak workloads, that follows a pattern i.e at the particular time. |
Spot Instance requests
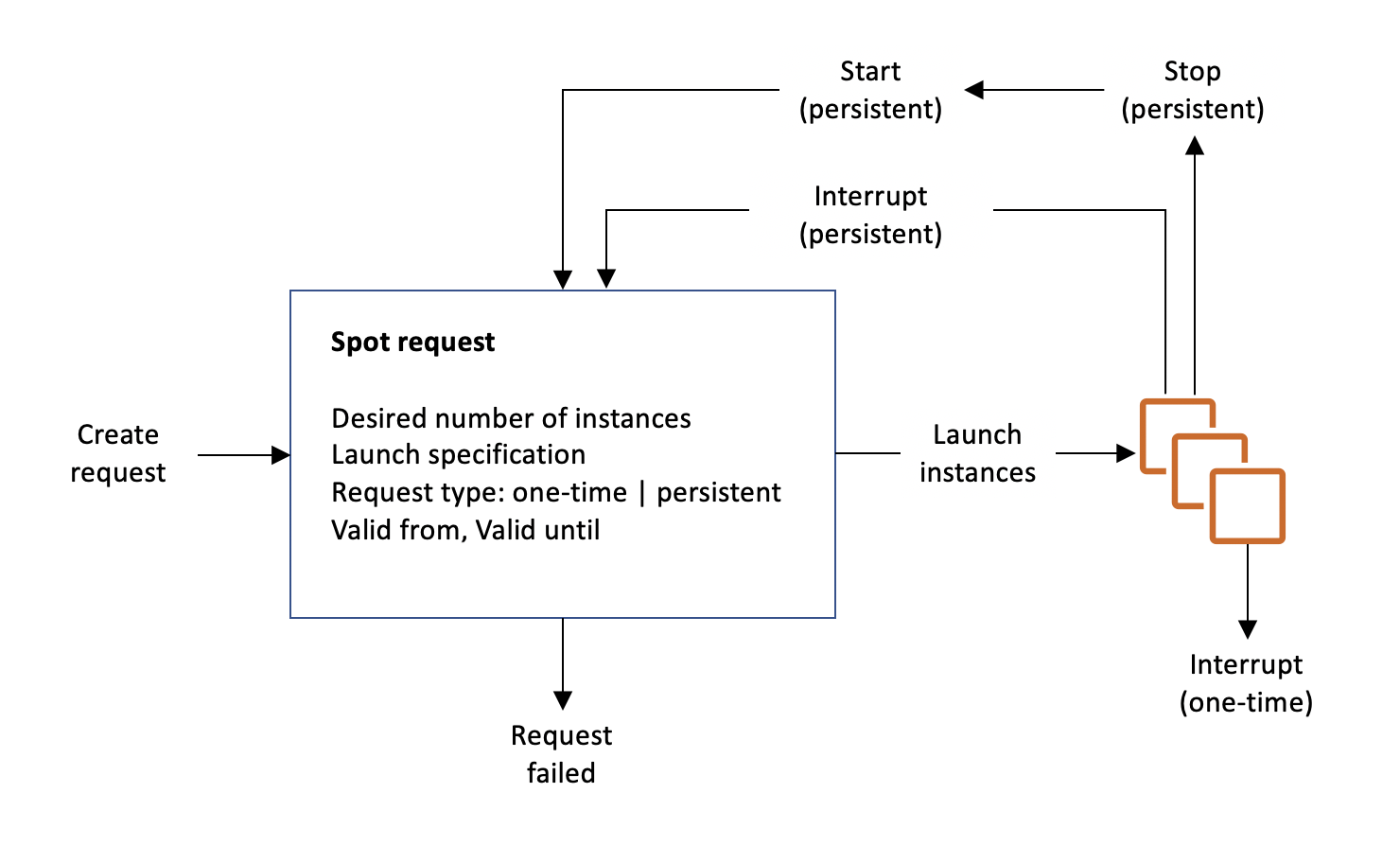
To use Spot Instances, you create a Spot Instance request that includes the desired number of instances, the instance type, the Availability Zone, and the maximum price that you are willing to pay per instance hour. If your maximum price exceeds the current Spot price, Amazon EC2 fulfills your request immediately if capacity is available. Otherwise, Amazon EC2 waits until your request can be fulfilled or until you cancel the request.
The following illustration shows how Spot Instance requests work. Notice that the request type (one-time or persistent) determines whether the request is opened again when Amazon EC2 interrupts a Spot Instance or if you stop a Spot Instance. If the request is persistent, the request is opened again after your Spot Instance is interrupted. If the request is persistent and you stop your Spot Instance, the request only opens after you start your Spot Instance.
Amazon Machine Image (AMI)
An Amazon Machine Image (AMI) provides the information required to launch an instance. You must specify an AMI when you launch an instance. You can launch multiple instances from a single AMI when you need multiple instances with the same configuration. You can use different AMIs to launch instances when you need instances with different configurations.
An AMI includes the following:
- One or more Amazon Elastic Block Store (Amazon EBS) snapshots, or, for instance-store-backed AMIs, a template for the root volume of the instance (for example, an operating system, an application server, and applications).
- Launch permissions that control which AWS accounts can use the AMI to launch instances.
- A block device mapping that specifies the volumes to attach to the instance when it’s launched.
Note : There are a lot of AMIs available in the AWS Marketplace, and you can create your own AMI and publish there.
EC2 Instance Metadata
Get the metadata of an EC2 instance using this URL : http://169.254.169.254/latest/meta-data/
AWS Storage
There are several services that AWS provides to store your data. Note that we are not referring to Databases here.
1. Elastic Block Storage (EBS)
Amazon Elastic Block Store (EBS) is an easy to use, high-performance block storage service designed for use with Amazon Elastic Compute Cloud (EC2) for both throughput and transaction-intensive workloads at any scale. Note that EBS is a virtual storage.
There are different EBS Volume Types.
| EBS Volume Type | Description |
| gp2/gp3 (SSD) | General purpose SSD volume that balances price and performance for a wide variety of workloads. |
| io1/io2 (SSD) | Highest-performance SSD volume for mission-critical low-latency or high-throughput workloads |
| st1/st2 (HDD) | Low cost HDD volume designed for frequency accessed, throughput-intensive workloads. |
| sc1 (HDD) | Lowest cost HDD volume designed for less frequently accessed workloads. |
Important : You can create a snapshot from an EBS Volume. If the Volume is encrypted, the snapshot will be encrypted as well. If an EBS Volume is created from an encrypted snapshot, the Volume will also be encrypted. When, an EC2 instance is terminated, the EBS Volume attached to it is deleted. However, when the instance is stopped or restarted, the Volume remains intact. Last but not the least, any volume, other than the root one, that is attached to the EC2 instance, remains intact, even after instance termination.
2. EC2 Instance Store
An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host computer. Instance store is ideal for temporary storage of information that changes frequently, such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances, such as a load-balanced pool of web servers.
Lifetime – You can specify instance store volumes for an instance only when you launch it. You can’t detach an instance store volume from one instance and attach it to a different instance.
The data in an instance store persists only during the lifetime of its associated instance. If an instance reboots (intentionally or unintentionally), data in the instance store persists. However, data in the instance store is lost under any of the following circumstances:
- The underlying disk drive fails
- The instance stops
- The instance hibernates
- The instance terminates
Therefore, do not rely on instance store for valuable, long-term data.
3. Elastic File System (EFS)
Amazon EFS provides scalable file storage for use with Amazon EC2. You can share an EFS file system and mount it on multiple EC2 instances. It is similar to an NFS filesystem.
4. S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can use Amazon S3 to store and protect any amount of data for a range of use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides management features so that you can optimize, organize, and configure access to your data to meet your specific business, organizational, and compliance requirements.
Below are the different S3 Storage Classes that AWS provides.
Note : Although there are different S3 storage classes, those classes can be associated at the object level and a single bucket can contain objects stored across S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA. You can also use S3 Lifecycle policies to automatically transition objects between storage classes without any application changes.
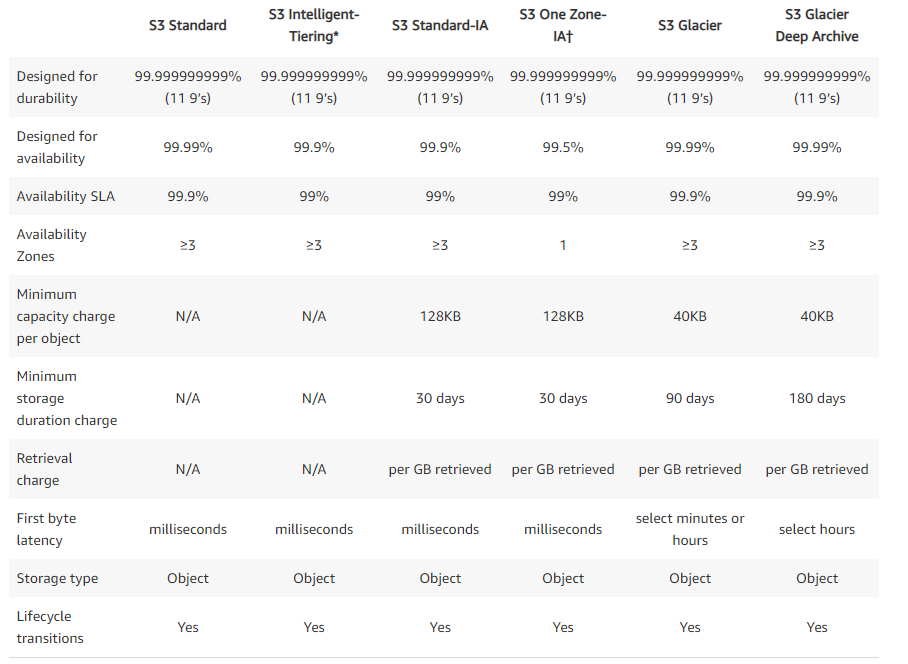
Note : All S3 storage classes share the same durability: 11 9s (99.999999999%). That’s often unintuitive, so it’s best to recall that all S3 classes have durability in common and decrease in availability from S3 Standard to S3-IA to S3 One Zone-IA to S3 Glacier. In addition, cost decreases in order from S3 Standard to S3-IA to S3 One Zone-IA to S3 Glacier. Last but not the least, carefully note the Minimum storage duration in each storage class. You cannot set an Object Lifecycle Policy to move the objects from one class to another before the minimum duration.
5. FSx
Amazon FSx is a fully managed file system solution. It uses SSD storage to provide fast performance with low latency. It comes in two flavours – one for windoes, and one for Linux.
Amazon FSx for Windows File Server – A fully managed third party native Microsoft Windows file system with full support for the SMB protocol, Windows NTFS, and Microsoft Active Directory (AD) integration. To migrate your existing file data into Amazon FSx, use Windows’s Robust File Copy (RoboCopy) to copy your files (both the data and the full set of metadata like ownership and Access Control Lists) directly to Amazon FSx.
Amazon FSx for Lustre – A high-performance file system optimized for fast processing of workloads for Linux systems. It provides sub-millisecond access to your data. Lustre is a popular open-source parallel file system. You can choose between SSD storage options and HDD storage options, each offering different levels of performance. The HDD options reduce storage costs by up to 80% for throughput-intensive workloads that don’t require the sub-millisecond latencies of SSD storage.
VPC
Amazon’s Virtual Private Cloud (VPC) is a foundational AWS service in both the Compute and Network AWS categories. Being foundational means that other AWS services, such as Elastic Compute Cloud (EC2), cannot be accessed without an underlying VPC network.
Each VPC creates an isolated virtual network environment in the AWS cloud, dedicated to your AWS account. Other AWS resources and services operate inside of VPC networks to provide cloud services.
Using VPC, you can quickly spin up a virtual network infrastructure that AWS instances can be launched into. Each VPC defines what your AWS resources need, including:
- IP addresses
- Subnets
- Routing
- Security
- Networking functionality
Note : All VPCs are created and exist in one—and only one—AWS region. AWS regions are geographic locations around the world where Amazon clusters its cloud data centers.
Important limitations
| Item | Limitation |
| One Region | Max 5 VPCs, Max 5 Elastic IPs |
| One VPC | Max 200 Subnets, Max 5 CIDR Blocks |
- A new account in AWS comes with a default VPC, that consists of:
- NACL
- Security Group
- Route Table
- Internet Gateway
- Subnet
2. Any VPC created manually doesn’t come with Subnets. You need to create the subnets separately.
3. When you create a subnet, AWS reserves 5 IPs for internal use, and you cannot assign those IPs.
4. There can be only one internet gateway per VPC
5. A Subnet is associated with a Route Table.
6. To create a NAT Instance, use any of the NAT Instance AMIs available in the AWS Marketplace, and you must disable “Source destination check”
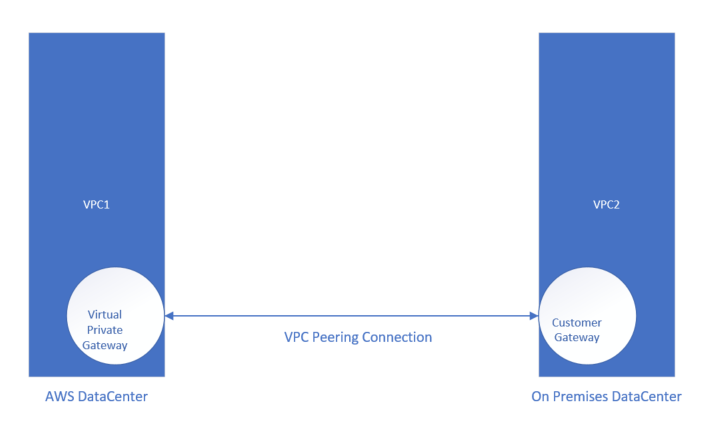
VPC Peering Connections
A VPC peering connection is a networking connection between two VPCs that enables you to route traffic between them privately. Instances in either VPC can communicate with each other as if they are within the same network. You can create a VPC peering connection between your own VPCs, with a VPC in another AWS account, or with a VPC in a different AWS Region.
AWS uses the existing infrastructure of a VPC to create a VPC peering connection; it is neither a gateway nor an AWS Site-to-Site VPN connection, and does not rely on a separate piece of physical hardware. There is no single point of failure for communication or a bandwidth bottleneck.
For more information about working with VPC peering connections, and examples of scenarios in which you can use a VPC peering connection, see the Amazon VPC Peering Guide.
NACL vs Security Group
| NACL | Security Group |
| Subnet Level | Instance Level |
| Stateless | Stateful |
| Blacklist Rules | Whitelist Rules |
Gist and Key Points about Various AWS Services
| Service Category | Service Name | Functionality | FAQs/Sample Question |
| Application Debugging | X-Ray | AWS X-Ray makes it easy for developers to analyze the behavior of their distributed applications by providing request tracing, exception collection, and profiling capabilities. | A multi-national retail company has multiple business divisions, with each division having its own AWS account. The engineering team at the company would like to debug and trace data across these AWS accounts and visualize it in a centralized account. |
| Monitoring | Amazon CloudWatch | Amazon CloudWatch collects monitoring and operational data to provide you with a unified view of AWS resources, services, and applications that run on AWS, and on-premises servers. | 1. CloudWatch has Metrics, Alarms and Events. Metrics – The parameter being monitored. Alarms – A condition e.g. threshold for the particular Metric Event – Based on an event pattern for a particular AWS service or a schedule, you can select a target to invoke. Common Actions include Stop/Start EC2 instance, Invoke a Lambda function and many more…. |
| Networking | VPC Flow Logs | It can create logs for IP traffic that flows in and out of a VPC. | 1. You can publish the VPC Flow logs to S3 bucket or CloudWatch Logs. 2. There can be more than one flow logs with different destinations. |
| NAT Instance | It is an EC2 instance with NAT capabilities. If your compute instance is located in a private subnet, and it wants to connect to the internet, it’s routing table is configured to connect to the NAT instance, which in turn is configured (configuration is in the NAT instance’s routing table), to connect to the internet. Note that the NAT instance should have the EC2 flag i.e. source/destination check disabled. Just like other EC2 instances, a NAT instance should be attached to a Security Group, and you need to completely manage the instance yourself e.g. patching, capacity etc. You need to connect an Elastic IP to a NAT instance. | 1. The NAT instance’s routing table is configured to talk to the IW (internet gateway) Note : A NAT instance can be used also as a Bastion Host. It also supports Port Forwarding, just like other EC2 instances. | |
| NAT Gateway | It does the same kind of routing as NAT instance, but it is completely managed by AWS. | 1. Better Bandwidth compared to NAT instance 2. Better availability 3. Created in a specific AZ Note : A NAT Gateway neither support Port Forwarding, nor support Bastion Host. | |
| Bastion Host | We can place a Bastion Host in our public subnet, so that only that Bastion Host can connect to your instances in the private subnet. | 1. You must make the Security Groups attached to Bastion Host extremely secure, so that it can only connect from specific desired IPs. 2. | |
| Management & Governance | CloudTrail | Continuously log your AWS account activity. Use CloudTrail to meet your governance, compliance, and auditing needs for your AWS accounts. | By default, CloudTrail logs are sent to an S3 bucket, that AWS creates on our behalf. We can create a CloudTrail Workflow, if we want to encrypt the logs, or send to CloudWatch Logs. |
| AWS Organizations | AWS Organizations helps you to centrally manage, control access and security, and share resources across your AWS accounts. | ||
| AWS Config | Record and evaluate configurations of your AWS resources AWS Config provides a detailed view of the resources associated with your AWS account, including how they are configured, how they are related to one another, and how the configurations and their relationships have changed over time. | ||
| VPN | Site to Site VPN | Using Site to Site VPN, you connect your corporate network to AWS VPC, and both seems part of the same network. | 1. A customer gateway is configured on the corporate DC 2. A Virtual Private Gateway is configured at the AWS end. |
| Transit Gateway | It can be used to transitively connect to AWS VPCs, VPN Connections and Direct Connect Gateway. | 1. You still have control on which network can talk to which VPC by configuring those in the route tables. 2. This is the only service in AWS that supports IP Multicast. | |
| IAM | Identity Access Management Service. You can define users, groups, and IAM roles. You can map the roles to specific predefined roles or group of roles, and use these roles to invoke other protected AWS services e.g. S3, RDS etc. | ||
| VPC | VPC Peering | VPC Peering is to connect two VPCs within the AWS network, and make them behave as if they are in the same network. Hence, those two VPCs cannot have overlapping CIDR. Also, this is a one to one connection, i.e. it can connect only two VPCs. | 1. VPC Peering works inter-region, cross account 2. To make a VPC Peering Connection work, you need to add the routes to the route tables of each of the VPCs. |
| VPC Endpoint | Any service exposed by AWS can be accessed within AWS using VPC Endpoint using a Private Network, without going to the internet. | There are 2 types of VPC Endpoints. Interface : Provisions an ENI as an entry point to most of the AWS Services. You must attach a Security Group to the ENI. Gateway : S3 & DynamoDB require Gateway VPC Endpoint | |
| Direct Connect (DX) | Provides a dedicated Private connection from your corporate network into your VPC | Use Cases: 1. Increased bandwidth throughput – working with large data sets – lower cost 2. Consistent network experience – real time data feeds Cons: 1. It takes months to setup Direct Connect (DX) | |
| Direct Connect Gateway | Used to connect your corporate network privately with multiple VPCs. | ||
| Elastic Beanstalk | |||
| S3 | 1. S3 Objects are private by default 2. You need to either make the S3 bucket public, or provide access to users using IAM Role. 3. An EC2 instance can access the S3 objects, only if it is attached to an IAM Role that allows access to the S3 bucket. | ||
| EBS | Elastic Block Storage for AWS | Amazon Elastic Block Store (EBS) is an easy to use, high-performance block storage service designed for use with Amazon Elastic Compute Cloud (EC2) for both throughput and transaction-intensive workloads at any scale. | |
| RDS (SQL Databases) | 1. MySQL 2. Oracle 3. MariaDB 4. PostgreSQL 5. MS SQL Server 6. Amazon Aurora | RDS stands for Relational Database. All the RDS services are self-managed, except Amazon Aurora, which is completely server less and managed by AWS, with very high scalability and availability. | Self-Managed RDS 1. You need to choose the underlying DB technology e.g. MySQL or Oracle etc. 2. You can build the DB instance using Production, Dev/Test or Free tier templates. 3. Need to define your admin user/password 4. Choose from 3 different type of instance classes, based on your compute, memory and network needs. Standard (m class instances) Standard instances provide a balance of compute, memory, and network resources, and is a good choice for many database workloads. Memory optimized classes (r and x class instances) Memory optimized instances accelerate performance for workloads that process large data sets in memory. Burstable classes (t class instances) Burstable performance instances provide a baseline level of CPU performance with the ability to burst above the baseline. 5. There are 3 different type of Storage you can choose from. General Purpose (SSD) storage is suitable for a broad range of database workloads. Provides baseline of 3 IOPS/GiB and ability to burst to 3,000 IOPS. Storage is between 20 – 16,384 GB. Provisioned IOPS (SSD) storage is suitable for I/O-intensive database workloads. Provides flexibility to provision I/O ranging from 1,000 to 80,000 IOPS. Storage is between 100 – 16,384 GB. Magnetic storage is for backward compatibility. We recommend that you use General Purpose SSD or Provisioned IOPS for any new storage needs. The maximum amount of storage allowed for DB instances on magnetic storage is less than that of the other storage types. 6. Multi-AZ Standby Instance is created by default for all RDS deployments. However, you can disable if you wish. Note that RDS provides Synchronous Standby instance, and fails over automatically, in case the Primary goes down. 6. You need to choose a Security Group for your RDS instances 7. DB backups are enabled by default and you can define retention period up to 35 days. Default is 7 days. Value can range from 0 – 35 days. 8. You can enable KMS encryption for data at rest. AWS Managed RDS – Aurora 1. Aurora supports only two underlying DB technology – MySQL or PostgreSQL 2. Capacity can be either Provisioned or Server less. You define the instance class (just like the self-managed RDS) for Provisioned, whereas for Server less, you just define the minimum and maximum resources (specifically RAM) needed, and AWS will scale accordingly. Server less is best suited for intermittent or unpredictable workloads. 3. You can create up to 15 read replicas of Aurora DB. Aurora Replica – Connects to the same storage volume as the primary DB instance and supports only read operations. Each Aurora DB cluster can have up to 15 Aurora Replicas in addition to the primary DB instance. Aurora automatically fails over to an Aurora Replica in case the primary DB instance becomes unavailable. You can specify the failover priority for Aurora Replicas. Aurora Replicas can also offload read workloads from the primary DB instance. |
| No SQL Databases | 1. DynamoDB 2. Amazon DocumentDB (MongoDB) 3. Amazon Keyspaces (Cassandra) 4. EMR (Elastic Map Reduce – Hadoop) | DynamoDB – DynamoDB is a fully WS managed, key-value, and document database that delivers single-digit-millisecond performance at any scale. It is a great fit for mobile, web, gaming, advertising technology, Internet of Things, and other applications. 1. You can define Provisioned or On Demand Capacity. 2. Reads and Writes are decoupled. Reads can be eventually consistent or strongly consistent. By Default, DynamoDB uses eventually consistent reads. 3. You can enable DAX (DynamoDB Accelerator) for read cache, to enhance read performance. 4. Data is encrypted at rest. You can use AWS provided fully managed key, your own key stored and managed by AWS KMS, or your own key managed by yourself. 5. You can only query on primary key, sort key or indexes in DynamoDB tables. 6. DynamoDB supports transactions | |
| ElastiCache | 1. Redis – In-memory data structure store used as database, cache and message broker. ElastiCache for Redis offers Multi-AZ with Auto-Failover and enhanced robustness. 2. Memcached – High-performance, distributed memory object caching system, intended for use in speeding up dynamic web applications. | While configuring Redis, you need to define number of Shards and number of replicas per shard. Number of Shards define the number of partitions of data that consists of 1 primary and up to 5 replicas. | |
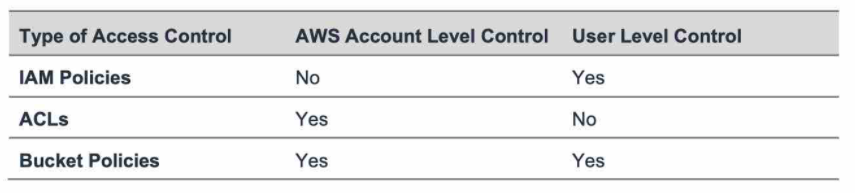
| S3 | Used for storing objects as key/value pairs | 1. Can store objects of size upto 5 TB 2. Server less, scales infinitely 3. Great option for big objects, not so great for small objects 4. Strong consistency Types of S3 S3 Standard, S3 IA, S3 One Zone IA, Glacier for backups [Ordered from most expensive to least expensive] Features Versioning, Cross-region replication, Encryption Security IAM, Bucket Policy, ACL [IAM servers as global policies, Bucket Policy and ACL serves as the Object level policies] ACL – Defines access to S3 buckets and objects for different AWS accounts. But default, full access is given to the object owner account. Note : ACL is attached to every bucket and its objects. Bucket Policy – Defines policy for the bucket in JSON format. You use policy generator to create these policies. Encryption SSE-S3, SSE-KMS, SSE-C, Client Side Encryption Bucket Name Rules Bucket names can consist only of lowercase letters, numbers, dots (.), and hyphens (-). There are many other rules as mentioned here Use Cases : Static files, big files, key/value pairs, website hosting Reliability : 99.999999999 [11 9s] Availability : 99.99% | 1. S3 bucket names are global, but the objects are regional 2. By default, S3 objects are private 3. You need to enable Bucket Versioning in order to implement MFA for accidental deletes. 4. Once you enable versioning, deleting will just add a DELETE marker to the current object. You can recover that object by just deleting the marker. 5. The minimum storage duration is 30 days before you can transition objects from S3 Standard to S3 One Zone-IA. S3 Lifecycle Policies/Rules Create Policies on S3 Objects/Object patterns to transition from S3-Standard to S3-OneZone-IA or S3-IA to reduce costs. Note that these transitions can be initiated only after 30 days of object creation in S3-Standard. The 30-days restriction doesn’t apply for transition to Glacier. Strong read-after-write consistency Amazon S3 delivers strong read-after-write consistency automatically, without changes to performance or availability, without sacrificing regional isolation for applications, and at no additional cost. After a successful write of a new object or an overwrite of an existing object, any subsequent read request immediately receives the latest version of the object. S3 also provides strong consistency for list operations, so after a write, you can immediately perform a listing of the objects in a bucket with any changes reflected. |
| Athena | Amazon Athena is a fast, cost-effective, interactive query service that makes it easy to analyze petabytes of data in S3 with no data warehouses or clusters to manage. | 1. Secured through IAM and S3 security. Use Cases : One Time SQL Queries, server less queries on S3, log analysis. We can use Athena to Query S3 logs, VPC Flow logs, ELB logs etc. | Cost : Pay per Query / TB of data scanned |
| Redshift | Redshift is a analytics and data warehousing service based on PostgreSQL, but it is NOT for OLTP, but it is OLAP (Online Analytical Processing) | 1. 10 times better performance that other data warehouses 2. Scales to PBs of data 3. Massively Parallel Query Execution 4. Columnar storage of data (instead of row based) 5. SQL interface for performing queries 6. Integration with BI Tools such as AWS Quicksight or Tableau | 1. Data can be loaded from S3, DynamoDB, DMS (Database Migration Service) or other DBs 2. Redshift Cluster can consist of 2 node up to 32 nodes, with 160 GB of space per node. 3. Redshift Clusters are in One Availability Zone (No Multi AZ) 4. Snapshots are point in time backups of a cluster, stored internally in S3. 5. Snapshots are incremental |
| Redshift Spectrum | Used to analyze data in S3, without loading into Redshift, but using the analytics capabilities provided by Redshift. | 1. Redshift is much high performance, analytics engine as compared to Athena. | |
| AWS Glue | Server less ETL solution in AWS | AWS Glue has another service called Glue Data Catalog, that stores metadata of tables/data from RDS, DynamoDB, S3 or other databases, and it can integrate with AWS Athena, Amazon Redshift Spectrum or Amazon EMR for data analytics. | |
| Neptune | Fully Managed Graph Database | Use Case : Database used for Social Networking, where there are a lot of convoluted links, and those links have other links. | |
| Elastic Search | ELK stack service in AWS. It can help to perform search on database on any fields. | Elasticsearch is a search engine based on the Lucene library. Amazon Elasticsearch Service is a fully managed service that makes it easy for you to deploy, secure, and run Elasticsearch cost-effectively at scale. You can build, monitor, and troubleshoot your applications using the tools you love, at the scale you need. The service provides support for open-source Elasticsearch APIs, managed Kibana, integration with Logstash and other AWS services, and built-in alerting and SQL querying. | |
| Auto Scaling Group | This is part of the EC2 services, and helps to scale out or scale in instances based on the desired capacity defined. It launches instances based on the launch configuration provided. | 1. If you want to run some script at the time of launching or at the time of termination, by keeping the instance in a wait state, you can use the Lifecycle Hooks. | |
| ECS | Elastic Container Service (Docker) | ||
| Fargate | Service to manage cluster of containers (just like Kubernetes) | ||
| Step Function | Helps to build visual workflow service used to orchestrate AWS services, automate business processes, and build server less applications. | ||
| AWS SageMaker | Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML. |
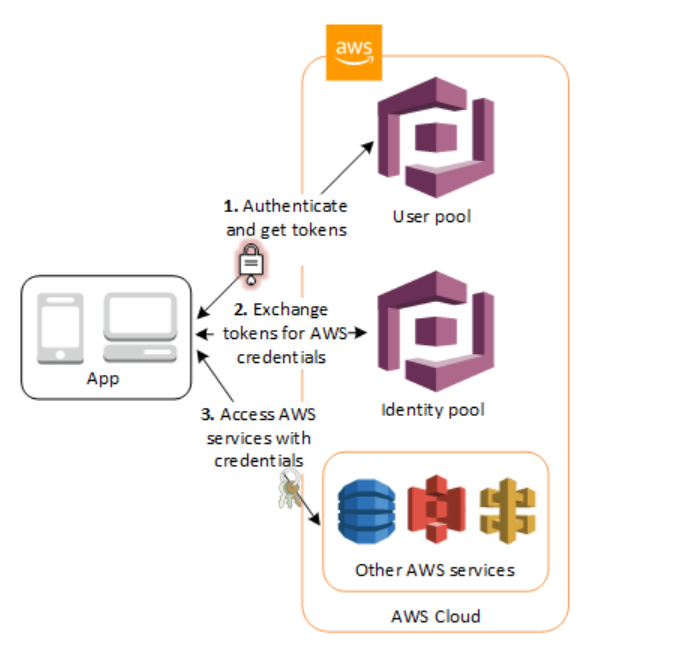
AWS Cognito
Amazon Cognito provides authentication, authorization, and user management for your web and mobile apps. Your users can sign in directly with a user name and password, or through a third party such as Facebook, Amazon, Google or Apple.
The two main components of Amazon Cognito are user pools and identity pools. User pools are user directories that provide sign-up and sign-in options for your app users. Identity pools enable you to grant your users access to other AWS services. You can use identity pools and user pools separately or together.
Launch Template vs Launch Configuration
A launch template is similar to a launch configuration, in that it specifies instance configuration information. It includes the ID of the Amazon Machine Image (AMI), the instance type, a key pair, security groups, and other parameters used to launch EC2 instances. However, defining a launch template instead of a launch configuration allows you to have multiple versions of a launch template.
With versioning of launch templates, you can create a subset of the full set of parameters. Then, you can reuse it to create other versions of the same launch template. For example, you can create a launch template that defines a base configuration without an AMI or user data script. After you create your launch template, you can create a new version and add the AMI and user data that has the latest version of your application for testing. This results in two versions of the launch template. Storing a base configuration helps you to maintain the required general configuration parameters. You can create a new version of your launch template from the base configuration whenever you want. You can also delete the versions used for testing your application when you no longer need them.
We recommend that you use launch templates to ensure that you’re accessing the latest features and improvements. Not all Amazon EC2 Auto Scaling features are available when you use launch configurations. For example, you cannot create an Auto Scaling group that launches both Spot and On-Demand Instances or that specifies multiple instance types. You must use a launch template to configure these features. For more information, see Auto Scaling groups with multiple instance types and purchase options.
With launch templates, you can also use newer features of Amazon EC2. This includes the current generation of EBS Provisioned IOPS volumes (io2), EBS volume tagging, T2 Unlimited instances, Elastic Inference, and Dedicated Hosts, to name a few. Dedicated Hosts are physical servers with EC2 instance capacity that are dedicated to your use. While Amazon EC2 Dedicated Instances also run on dedicated hardware, the advantage of using Dedicated Hosts over Dedicated Instances is that you can bring eligible software licenses from external vendors and use them on EC2 instances.
If you currently use launch configurations, you can migrate data from your existing launch configurations to launch templates by copying them in the console. Then, you can migrate your deployed Auto Scaling groups that use a launch configuration to a new launch template. To do this, start an instance refresh to do a rolling update of your group. For more information, see Replacing Auto Scaling instances based on an instance refresh.
When you create a launch template, all parameters are optional. However, if a launch template does not specify an AMI, you cannot add the AMI when you create your Auto Scaling group. If you specify an AMI but no instance type, you can add one or more instance types when you create your Auto Scaling group.
Once created, you cannot modify a Launch Configuration, but you can modify a Launch Template by creating a new version.
AWS Shield
AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency. There are two tiers of AWS Shield – Standard and Advanced.
AWS Shield Standard is included with your AWS services at no additional cost.
AWS Shield Advanced pricing is detailed on the AWS Shield Advanced Pricing page. The additional cost for AWS Shield Advanced includes basic AWS WAF protections for the resources that you protect with AWS Shield Advanced. Basic AWS WAF protections include your web ACLs, the rule groups that you manage, and any AWS Managed Rules that are provided free of charge with AWS WAF. AWS Shield Advanced costs do not cover additional paid features for AWS WAF, such as the use of the AWS WAF Bot Control rule group or AWS Marketplace rule groups.
AWS Shield Advanced charges do not increase with attack volume. This provides a predictable cost for your extended protection.
The AWS Shield Advanced fee applies for each business that is subscribed to AWS Shield Advanced. If your business has multiple AWS accounts, you pay just one Shield Advanced monthly fee as long as all the AWS accounts are in the same Consolidated Billing account family. Further, you must own all the AWS accounts and resources in the account.
AWS GuardDuty
Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts, workloads, and data stored in Amazon S3. With the cloud, the collection and aggregation of account and network activities is simplified, but it can be time-consuming for security teams to continuously analyze event log data for potential threats. With GuardDuty, you now have an intelligent and cost-effective option for continuous threat detection in AWS. The service uses machine learning, anomaly detection, and integrated threat intelligence to identify and prioritize potential threats.
GuardDuty analyzes tens of billions of events across multiple AWS data sources, such as AWS CloudTrail events, Amazon VPC Flow Logs, and DNS logs.
With a few clicks in the AWS Management Console, GuardDuty can be enabled with no software or hardware to deploy or maintain. By integrating with Amazon CloudWatch Events, GuardDuty alerts are actionable, easy to aggregate across multiple accounts, and straightforward to push into existing event management and workflow systems.
Amazon Macie
Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data on Amazon S3. Macie automatically detects a large and growing list of sensitive data types, including personally identifiable information (PII) such as names, addresses, and credit card numbers. It also gives you constant visibility of the data security and data privacy of your data stored in Amazon S3.
SQS
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating message oriented middleware, and empowers developers to focus on differentiating work. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available.
SQS offers two types of message queues. Standard queues offer maximum throughput, best-effort ordering, and at-least-once delivery. SQS FIFO queues are designed to guarantee that messages are processed exactly once, in the exact order that they are sent.
By default, FIFO queues support up to 3,000 messages per second with batching, or up to 300 messages per second (300 send, receive, or delete operations per second) without batching. Therefore, using batching you can meet a throughput requirement of upto 3,000 messages per second.
The name of a FIFO queue must end with the .fifo suffix. The suffix counts towards the 80-character queue name limit. To determine whether a queue is FIFO, you can check whether the queue name ends with the suffix.
If you have an existing application that uses standard queues and you want to take advantage of the ordering or exactly-once processing features of FIFO queues, you need to configure the queue and your application correctly. You can’t convert an existing standard queue into a FIFO queue. To make the move, you must either create a new FIFO queue for your application or delete your existing standard queue and recreate it as a FIFO queue.
Placement Groups
When you launch a new EC2 instance, the EC2 service attempts to place the instance in such a way that all of your instances are spread out across underlying hardware to minimize correlated failures. You can use placement groups to influence the placement of a group of interdependent instances to meet the needs of your workload. Depending on the type of workload, you can create a placement group using one of the following placement strategies:
Cluster placement group
Partition placement group
Spread placement group.
A Spread placement group is a group of instances that are each placed on distinct racks, with each rack having its own network and power source.
Spread placement groups are recommended for applications that have a small number of critical instances that should be kept separate from each other. Launching instances in a spread placement group reduces the risk of simultaneous failures that might occur when instances share the same racks.
A spread placement group can span multiple Availability Zones in the same Region. You can have a maximum of seven running instances per Availability Zone per group. Therefore, to deploy 15 EC2 instances in a single Spread placement group, the company needs to use 3 AZs.
More information on Placement groups here.
| AWS Global Accelerator | AWS Cloudfront |
| AWS Global Accelerator is a networking service that helps you improve the availability and performance of the applications that you offer to your global users. AWS Global Accelerator is easy to set up, configure, and manage. It provides static IP addresses that provide a fixed entry point to your applications and eliminate the complexity of managing specific IP addresses for different AWS Regions and Availability Zones. AWS Global Accelerator always routes user traffic to the optimal endpoint based on performance, reacting instantly to changes in application health, your user’s location, and policies that you configure. Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP. For blue green deployments, AWS Global Accelerator can shift traffic gradually or all at once between the blue and the green environment and vice-versa without being subject to DNS caching on client devices and internet resolvers, traffic dials and endpoint weights changes are effective within seconds. | Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment. CloudFront points of presence (POPs) (edge locations) make sure that popular content can be served quickly to your viewers. CloudFront also has regional edge caches that bring more of your content closer to your viewers, even when the content is not popular enough to stay at a POP, to help improve performance for that content. Regional edge caches help with all types of content, particularly content that tends to become less popular over time. Examples include user-generated content, such as video, photos, or artwork; e-commerce assets such as product photos and videos; and news and event-related content that might suddenly find new popularity. CloudFront supports HTTP/RTMP protocol based requests. |
VPC Launch Wizard provides 4 options
- One Public Subnet Only
- One Public and One Private Subnet
- One Private Subnet with VPN access
- One Public and One Private Subnet with VPN access
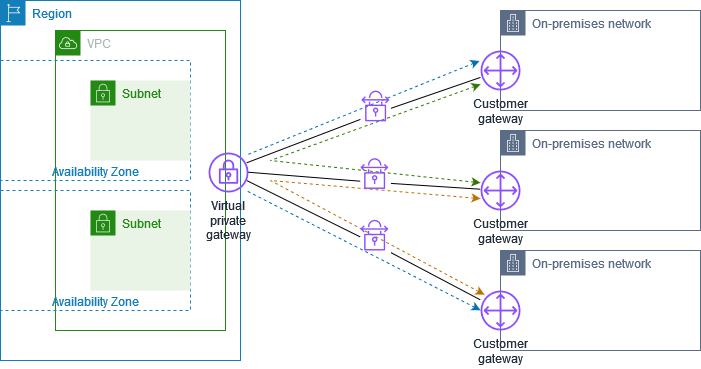
VPN CloudHub
Use Case : A media company has its corporate headquarters in Los Angeles with an on-premises data center using an AWS Direct Connect connection to the AWS VPC. The branch offices in San Francisco and Miami use Site-to-Site VPN connections to connect to the AWS VPC. The company is looking for a solution to have the branch offices send and receive data with each other as well as with their corporate headquarters.
Solution : If you have multiple AWS Site-to-Site VPN connections, you can provide secure communication between sites using the AWS VPN CloudHub. This enables your remote sites to communicate with each other, and not just with the VPC. Sites that use AWS Direct Connect connections to the virtual private gateway can also be part of the AWS VPN CloudHub. The VPN CloudHub operates on a simple hub-and-spoke model that you can use with or without a VPC. This design is suitable if you have multiple branch offices and existing internet connections and would like to implement a convenient, potentially low-cost hub-and-spoke model for primary or backup connectivity between these remote offices.
Per the given use-case, the corporate headquarters has an AWS Direct Connect connection to the VPC and the branch offices have Site-to-Site VPN connections to the VPC. Therefore using the AWS VPN CloudHub, branch offices can send and receive data with each other as well as with their corporate headquarters.
VPN CloudHub
S3 Access Controls
AWS Lambda
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume – there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration. Just upload your code, and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
Services that Lambda reads events from
- Amazon DynamoDB
- Amazon Kinesis
- Amazon MQ
- Amazon Managed Streaming for Apache Kafka
- self-managed Apache Kafka
- Amazon Simple Queue Service
Services that invoke Lambda functions synchronously
- Elastic Load Balancing (Application Load Balancer)
- Amazon Cognito
- Amazon connect
- Amazon Lex
- Amazon Alexa
- Amazon API Gateway
- Amazon CloudFront (Lambda@Edge)
- Amazon Kinesis Data Firehose
- Amazon Simple Storage Service Batch
- Secrets Manager
Services that invoke Lambda functions asynchronously
- Amazon Simple Storage Service
- Amazon Simple Notification Service
- Amazon Simple Email Service
- AWS CloudFormation
- Amazon CloudWatch Logs
- Amazon CloudWatch Events
- AWS CodeCommit
- AWS Config
- AWS IoT
- AWS IoT Events
- AWS CodePipeline
Services that integrate with Lambda in other ways
Enabling VPC for Lambda Functions – Lambda functions always operate from an AWS-owned VPC. By default, your function has the full ability to make network requests to any public internet address — this includes access to any of the public AWS APIs. For example, your function can interact with AWS DynamoDB APIs to PutItem or Query for records. You should only enable your functions for VPC access when you need to interact with a private resource located in a private subnet. An RDS instance is a good example.
Once your function is VPC-enabled, all network traffic from your function is subject to the routing rules of your VPC/Subnet. If your function needs to interact with a public resource, you will need a route through a NAT gateway in a public subnet.
Lambda Layers – Create layers to separate your function code from its dependencies. A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies. With layers, you can use libraries in your function without needing to include them in your deployment package.
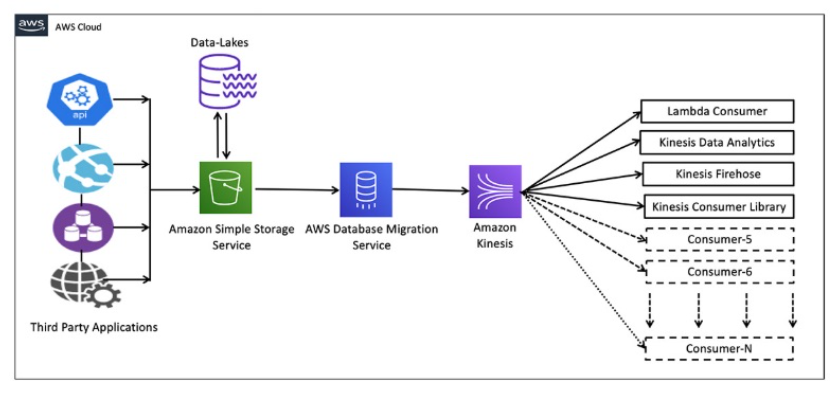
AWS Database Migration Service (AWS DMS)
AWS DMS enables you to seamlessly migrate data from supported sources to relational databases, data warehouses, streaming platforms, and other data stores in AWS cloud. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. The AWS Database Migration Service can migrate your data to and from most widely used commercial and open-source databases.
Use Cases
1. Homogeneous database migrations
You create a migration task with connections to the source and target databases, then start the migration with the click of a button. AWS Database Migration Service takes care of the rest.
2. Heterogenous database migrations
Use the AWS Schema Conversion Tool to convert the source schema and code to match that of the target database, and then use the AWS Database Migration Service to migrate data from the source database to the target database.
3. Database consolidation
You can use AWS Database Migration Service to consolidate multiple source databases into a single target database. This can be done for homogeneous and heterogeneous migrations, and you can use this feature with all supported database engines.
4. Continuous data replication
Continuous data replication has a multitude of use cases including Disaster Recovery instance synchronization, geographic database distribution and Dev/Test environment synchronization. You can use DMS for both homogeneous and heterogeneous data replications for all supported database engines.
Sample Use case for S3 to AWS Kinesis streaming using DMS
AWS Resource Access Manager
RAM allows to Share AWS resources with other AWS accounts.
Kinesis Use Case
An Internet-of-Things (IoT) company would like to have a streaming system that performs real-time analytics on the ingested IoT data. Once the analytics is done, the company would like to send notifications back to the mobile applications of the IoT device owners.
Solution :
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application.
With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis enables you to process and analyze data as it arrives and respond instantly instead of having to wait until all your data is collected before the processing can begin.
Kinesis will be great for event streaming from the IoT devices, but not for sending notifications as it doesn’t have such a feature.
Amazon Simple Notification Service (SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging. SNS is a notification service and will be perfect for this use case.
Streaming data with Kinesis and using SNS to send the response notifications is the optimal solution for the current scenario.
Optimize cost with EC2 instances and other services
AWS Cost Explorer helps you identify under-utilized EC2 instances that may be downsized on an instance by instance basis within the same instance family, and also understand the potential impact on your AWS bill by taking into account your Reserved Instances and Savings Plans.
AWS Compute Optimizer recommends optimal AWS Compute resources for your workloads to reduce costs and improve performance by using machine learning to analyze historical utilization metrics. Compute Optimizer helps you choose the optimal Amazon EC2 instance types, including those that are part of an Amazon EC2 Auto Scaling group, based on your utilization data.
Permission Boundary
A permissions boundary can be used to control the maximum permissions employees can grant to the IAM principals (that is, users and roles) that they create and manage. As the IAM administrator, you can define one or more permissions boundaries using managed policies and allow your employee to create a principal with this boundary. The employee can then attach a permissions policy to this principal. However, the effective permissions of the principal are the intersection of the permissions boundary and permissions policy. As a result, the new principal cannot exceed the boundary that you defined.
Permission Boundary Example: 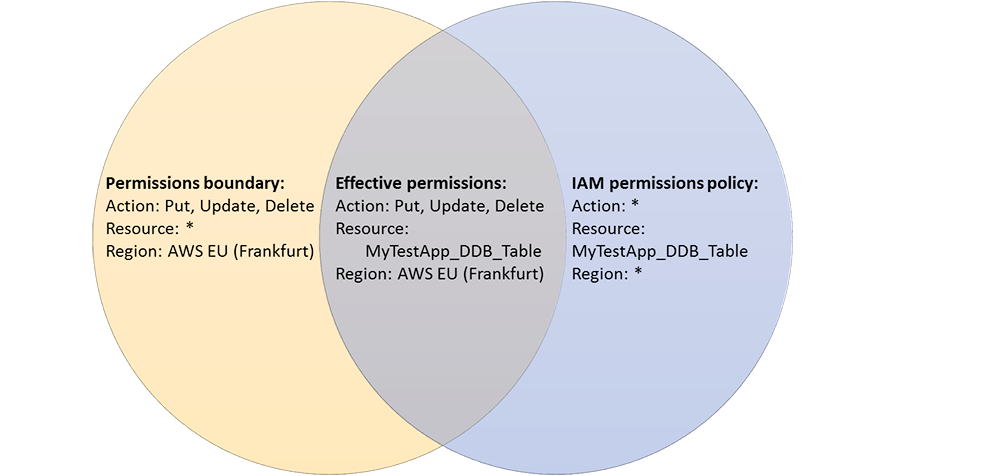
AWS S3 Sync Command to copy objects from one S3 to another
The aws S3 sync command uses the CopyObject APIs to copy objects between S3 buckets. The sync command lists the source and target buckets to identify objects that are in the source bucket but that aren’t in the target bucket. The command also identifies objects in the source bucket that have different LastModified dates than the objects that are in the target bucket. The sync command on a versioned bucket copies only the current version of the object—previous versions aren’t copied. By default, this preserves object metadata, but the access control lists (ACLs) are set to FULL_CONTROL for your AWS account, which removes any additional ACLs. If the operation fails, you can run the sync command again without duplicating previously copied objects.
You can use the command like so:
aws s3 sync s3://DOC-EXAMPLE-BUCKET-SOURCE s3://DOC-EXAMPLE-BUCKET-TARGET
How to provide security of EFS?
1. Use VPC security groups to control the network traffic to and from your file system
2. Attach an IAM policy to your file system to control clients who can mount your file system with the required permissions
3. Use EFS Access Points to manage application access
Increase Performance of DynamoDB and S3 bases applications
Enable DynamoDB Accelerator (DAX) for DynamoDB and CloudFront for S3
DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for Amazon DynamoDB that delivers up to a 10 times performance improvement—from milliseconds to microseconds—even at millions of requests per second.
DAX is tightly integrated with DynamoDB—you simply provision a DAX cluster, use the DAX client SDK to point your existing DynamoDB API calls at the DAX cluster, and let DAX handle the rest. Because DAX is API-compatible with DynamoDB, you don’t have to make any functional application code changes. DAX is used to natively cache DynamoDB reads.
CloudFront is a content delivery network (CDN) service that delivers static and dynamic web content, video streams, and APIs around the world, securely and at scale. By design, delivering data out of CloudFront can be more cost-effective than delivering it from S3 directly to your users.
When a user requests content that you serve with CloudFront, their request is routed to a nearby Edge Location. If CloudFront has a cached copy of the requested file, CloudFront delivers it to the user, providing a fast (low-latency) response. If the file they’ve requested isn’t yet cached, CloudFront retrieves it from your origin – for example, the S3 bucket where you’ve stored your content.
So, you can use CloudFront to improve application performance to serve static content from S3.
Issue with huge number of producers and consumers with KDS in between
Use Case : A big data analytics company is using Kinesis Data Streams (KDS) to process IoT data from the field devices of an agricultural sciences company. Multiple consumer applications are using the incoming data streams and the engineers have noticed a performance lag for the data delivery speed between producers and consumers of the data streams.
Solution : Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events.
By default, the 2MB/second/shard output is shared between all of the applications consuming data from the stream. You should use enhanced fan-out if you have multiple consumers retrieving data from a stream in parallel. With enhanced fan-out developers can register stream consumers to use enhanced fan-out and receive their own 2MB/second pipe of read throughput per shard, and this throughput automatically scales with the number of shards in a stream.
Kinesis Data Streams Fanout 
High Performance Filesystem
Amazon FSx for Lustre
Amazon FSx for Lustre makes it easy and cost-effective to launch and run the world’s most popular high-performance file system. It is used for workloads such as machine learning, high-performance computing (HPC), video processing, and financial modeling. The open-source Lustre file system is designed for applications that require fast storage – where you want your storage to keep up with your compute. FSx for Lustre integrates with Amazon S3, making it easy to process data sets with the Lustre file system. When linked to an S3 bucket, an FSx for Lustre file system transparently presents S3 objects as files and allows you to write changed data back to S3.
Filesystem for Windows
Amazon FSx for Windows File Server – Amazon FSx for Windows File Server provides fully managed, highly reliable file storage that is accessible over the industry-standard Service Message Block (SMB) protocol. It is built on Windows Server, delivering a wide range of administrative features such as user quotas, end-user file restore, and Microsoft Active Directory (AD) integration. FSx for Windows does not allow you to present S3 objects as files and does not allow you to write changed data back to S3.
Improve S3 file upload speed
Use Amazon S3 Transfer Acceleration to enable faster file uploads into the destination S3 bucket – Amazon S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Transfer Acceleration takes advantage of Amazon CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
Use multipart uploads for faster file uploads into the destination S3 bucket – Multipart upload allows you to upload a single object as a set of parts. Each part is a contiguous portion of the object’s data. You can upload these object parts independently and in any order. If transmission of any part fails, you can retransmit that part without affecting other parts. After all parts of your object are uploaded, Amazon S3 assembles these parts and creates the object. In general, when your object size reaches 100 MB, you should consider using multipart uploads instead of uploading the object in a single operation. Multipart upload provides improved throughput, therefore it facilitates faster file uploads.
Sample AWS Architectures and Solutions
https://aws.amazon.com/solutions
https://aws.amazon.com/architecture